02 · 核心思路
冻结模型,只把"图书管理员"做扎实
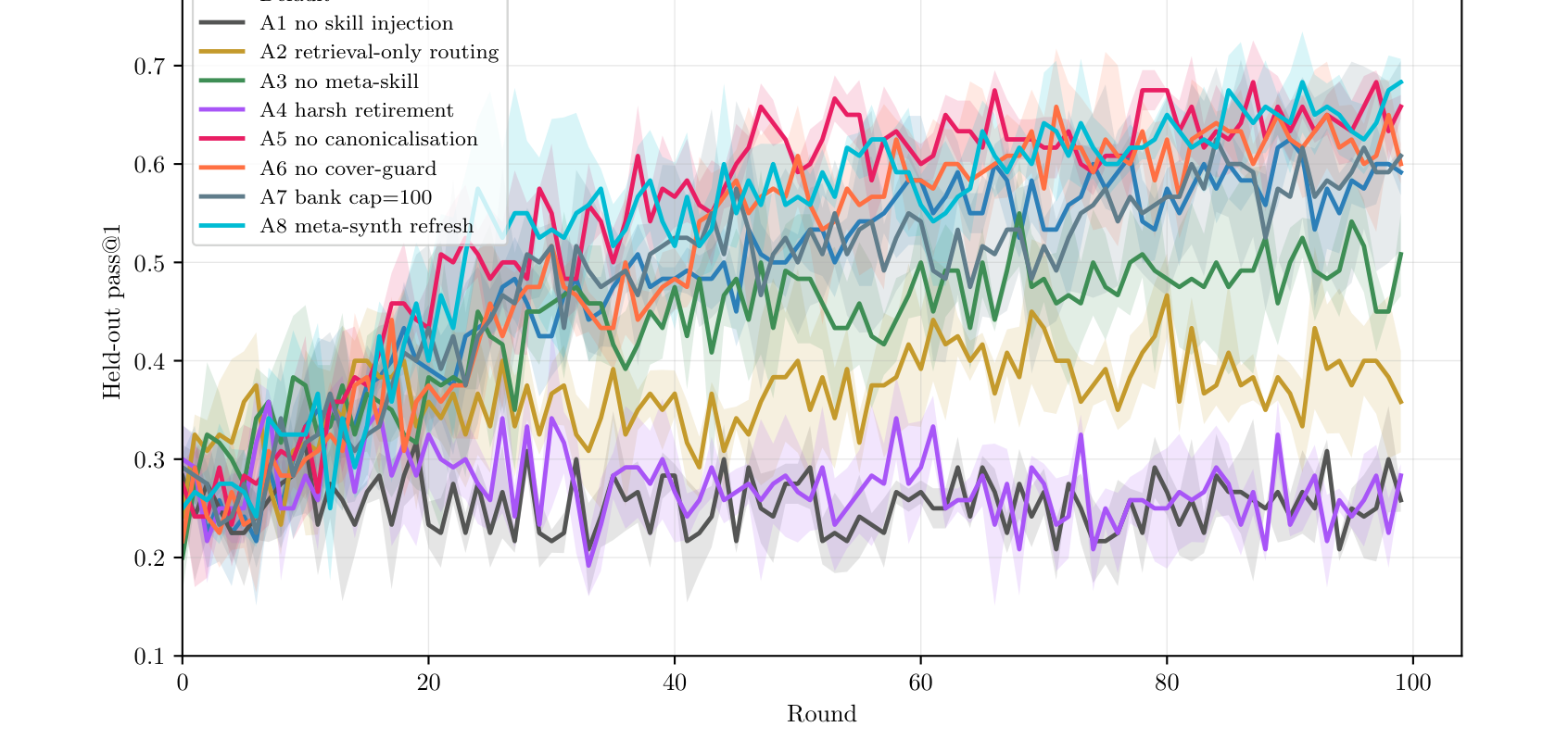
Ratchet 的设定很克制:同一个冻结的 LLM 扮演所有角色,不改一丝权重,整个系统的"成长"只发生在外部的库和账本里(用 SQLite 持久化)。它把流程分成三条带子——上面"解题"、中间"存东西"、下面"复盘+管理库"。下图是全貌,看不懂没关系,紧接着用人话拆解每个角色。
- 推理带(蓝,每道题走一遍):题目 → 挑笔记(Router 从库里选 0–1 条相关经验)→ 解题(Solver 读着经验写代码)→ 判分(Grader 跑测试,对/错)→ 把这次 (题, 用了哪条经验, 对错) 打包成一条战绩记录。
- 记忆带(黄,持久化、只追加):技能库(所有经验,含已下架的,永不物理删除)、模板(一份"好经验长什么样"的写作规范,全局唯一)、战绩账本(所有战绩记录 + 复盘结论)。系统的全部"状态"都在这三处,模型本身不变。
- 反思带(绿,每轮跑一次):复盘(Critic 给每条失败记录归因:经验是帮了倒忙还是没用上)→ 写新经验(Synthesizer 把反复出现的同类失败照模板写成新技能)→ 清理(Curator 按战绩把长期帮倒忙的技能下架)。另有一个慢周期的重写模板(Meta-Synth,默认关闭)。
六个角色,都是同一个 LLM + 一本库,换个提示词而已
页面后面会反复提到这几个角色。这里给一张"人话对照表",记住左边的动作名就够了,括号里的英文只是方便对回原文:
推理 · 做题
挑笔记 Router
从库里挑 0 或 1 条最相关的经验,塞给解题的人。库大了先粗筛再让 LLM 拍板选哪条。
推理 · 做题
解题 Solver
冻结的 LLM 读着挑出来的经验,把题做了。单次调用,不反思、不调工具。
推理 · 做题
判分 Grader
跑测试看对错。这是"客观战绩"的唯一来源,写进战绩账本。
反思 · 管库
复盘 Critic
对每条失败记录归因:这次用的经验是帮了倒忙、没用上、还是无关。只用固定标签,避免乱编理由。
反思 · 管库
写新经验 Synthesizer
把最近反复出现的同类失败,照"模板"总结成一条新技能入库。
反思 · 管库
清理 Curator
按账本算每条经验的战绩,长期帮倒忙的下架(改状态,不删除)。库满了也淘汰战绩最差的。
记住一个对应关系:"挑笔记 / 解题 / 判分"是用这本手册;"复盘 / 写新经验 / 清理"是管这本手册。整篇文章的核心发现,全在"管"这一侧。