QUEST:用全合成数据训练前沿深度研究 Agent
阅读原文 ↗ · arXiv:2605.24218深度研究 Agent 不只是回答问题——它要搜索、验证、记忆、综合,在长时间跨度里产出带引用的报告。但前沿系统(OpenAI DeepResearch、Claude Research 等)都是闭源的,开源方案往往只擅长某一类任务。
QUEST 用仅 8K 条全合成训练数据,把 2B–35B 的开源模型训练成通用深度研究 Agent,同时覆盖事实检索、引用落地、报告综合三大能力。核心配方:基于 Rubric Tree 的数据合成管线 + 结构化上下文压缩 + MT → SFT → RL 三阶段训练。
(从 2 万条筛选)
超越 OpenAI-DR (47.0%)
超越 GPT-5 (76.4%)
代码 + 数据 + 权重
这篇论文要解决什么问题?
搜索引擎正在从「返回网页列表」进化到「自主检索证据并综合知识」。深度研究 Agent 接到复杂任务后,会分解子目标、执行搜索、阅读网页、产出带引用的回答或长报告。
但训练这样的 Agent 很难,因为深度研究任务横跨两种评估范式:
- 客观任务:答案可被外部证据验证(如 BrowseComp 找冷门事实、GAIA 多步推理)
- 开放任务:需要主观评判报告质量(如 DeepResearch Bench 的长篇研究报告)
论文指出,一个通用深度研究 Agent 需要同时具备三种能力——而现有 benchmark 和训练方案往往只覆盖其中一种:
传统 QA 监督只看「答案对不对」,无法处理多解任务、开放报告和细粒度信用分配。QUEST 的切入点就是:用 Rubric Tree 把任务约束结构化,让训练和评估都有可验证的细粒度信号。
核心创新一:Rubric Tree 数据合成管线
QUEST 的训练数据不是人工标注的 QA 对,而是 Quest-8K:每条数据包含一个复杂查询、一棵任务专属的 Rubric Tree、以及对应的评估协议。从 2 万条候选中严格筛选到 8,161 条。
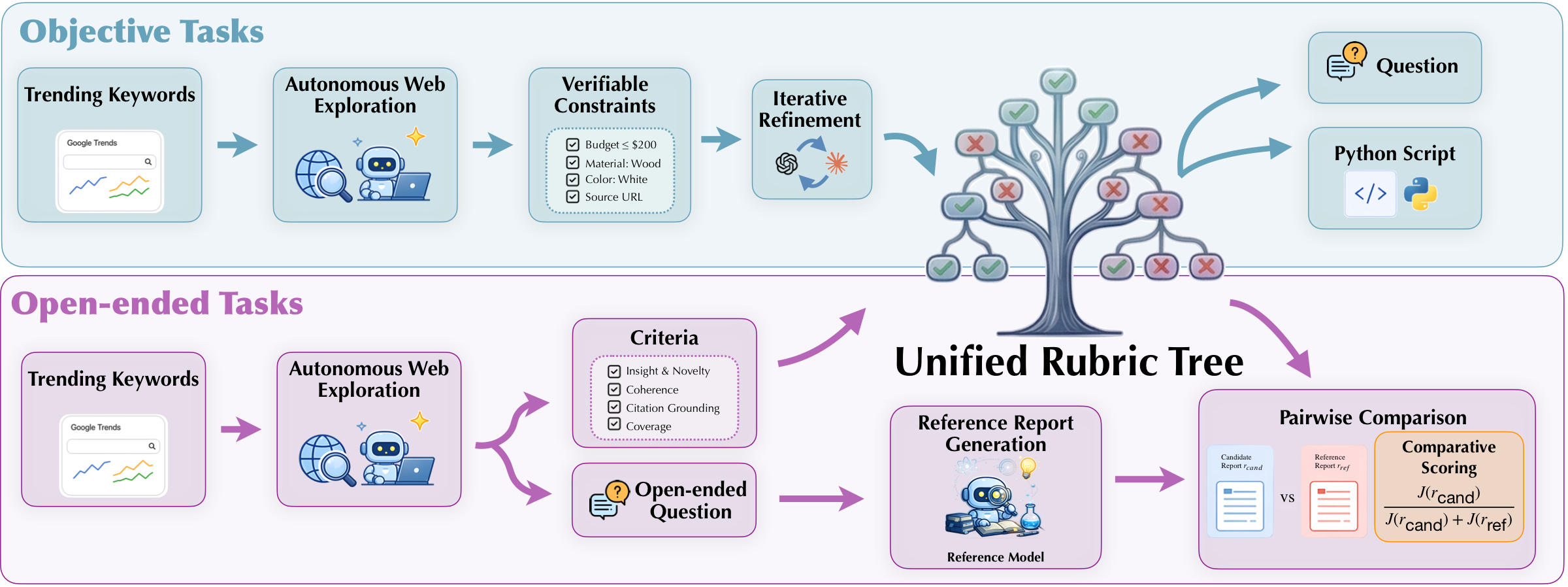
图:数据合成管线总览。上半部分是生成流程,下半部分是客观任务和开放任务的 Rubric Tree 示例。灰色为根节点,蓝色为中间分支,红色为可自动验证的叶子节点。
展开说明 ▸- 种子采样:从 Google Trends 爬取热门关键词作为主题种子,保证任务时效性和多样性。
- 网页探索:用 Claude Sonnet 4.5 自主浏览网页,收集信息并提取可验证约束。
- 树构建与精炼:约束组织为层次化 Rubric Tree,经多轮精炼和验证后丢弃结构不一致的任务。
- 问题生成:将 Rubric Tree 翻译为自然语言查询;客观任务额外用 GPT-5 生成 Python 评估脚本。
- 客观 vs 开放:客观任务用任务专属树;开放任务在根节点固定四个共享维度(指令遵循、全面性、可读性、洞察力),子节点按任务自适应生成。
- 开放任务评分:生成参考报告 → LLM judge 对候选和参考同时打分 → 归一化为相对分数 Score = J(cand) / (J(cand) + J(ref))。
Rubric Tree 的结构
根节点代表总分,从子节点聚合。叶子节点是可二元验证的具体约束(事实正确性、来源归属等),内部节点递归分解更高层约束。这种设计带来两个关键好处:
- 统一框架:唯一答案、多解、开放报告都在同一棵树里表达
- 细粒度信号:根节点部分得分比二元对错更适合 RL 的信用分配
官方数据示例 · 来自 osunlp/QUEST-RL-Data · task_id: tree2py_traj_104 · 类别: Outdoor & Recreation
一条真实数据是怎么变成 Rubric Tree 的?
下面用数据集中第 104 号客观任务走一遍完整流程。这类任务的最终产物是:自然语言问题 + 验证树 + 可执行的 Python 评估脚本(tree2py)。
核心创新二:结构化上下文管理
深度研究 Agent 在多轮搜索中上下文会迅速膨胀。现有开源方案要么限制轮数,要么依赖超大上下文窗口硬撑。QUEST 的做法是:当上下文超过阈值时,用 Context Condenser(GPT-5-mini)把全部历史压缩为一个结构化的 Context State,然后在全新上下文窗口中继续。
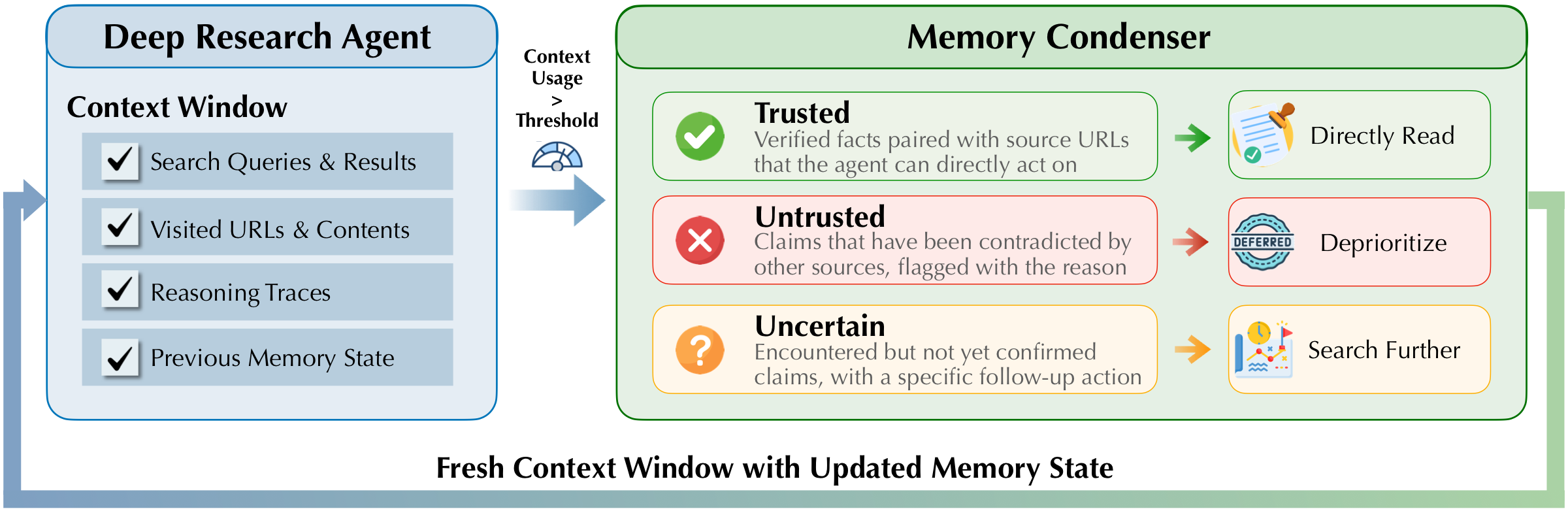
图:上下文超阈值时,Context Condenser 将历史压缩为 Context State,Agent 在新窗口中继续推理。
展开说明 ▸- 触发条件:上下文窗口使用率超过阈值时启动压缩。
- 输入:完整原始历史——搜索查询与结果、访问过的 URL 及提取内容、推理轨迹、之前的摘要记忆。
- 输出:更新后的 Context State JSON,分三个桶组织知识。
- 恢复推理:Agent 在新上下文窗口中以 Context State 为初始状态继续工作。
- 后续引导:Uncertain 条目指导下一步搜索和验证;Untrusted 条目被降权,除非需要进一步核实。
✓ Trusted
已与来源 URL 交叉验证的事实,可直接复用,无需重复搜索
✗ Untrusted
被其他来源反驳的声明,标注不信任原因,默认不再使用
? Uncertain
部分支持的声明,附待访问 URL 或待重跑的查询,驱动后续验证
Context State 编码了 Agent 的认知状态(epistemic state)——恢复后的 Agent 知道「已确认什么、怀疑什么、还需验证什么」,避免冗余工具调用,支持跨长程任务的连贯引用综合。
核心创新三:MT → SFT → RL 训练管线
QUEST 的训练分三阶段,每阶段解决不同问题。三者缺一不可——消融实验表明 MT+SFT+RL 组合在所有 benchmark 上综合最优。
阶段 1:Mid-Training(MT)
两个辅助任务,让基座模型学会长上下文理解和 Context State 结构——不需要额外标注,直接复用数据合成管线的副产品:
- 上下文摘要:给定长历史,输出 Context State JSON(监督来自 GPT-5-mini 在合成过程中的摘要)
- 相关信息提取:给定原始 HTML 和提取目标,过滤导航栏、广告等噪声(监督来自 visit 工具轨迹)
阶段 2:Supervised Fine-Tuning(SFT)
用教师模型 Tongyi DeepResearch 在 Quest-8K 上收集完整 Agent 轨迹。评估分数超过阈值才保留;客观任务不达标时注入评估反馈做 reflection retry。开放任务用 GPT-5.2 润色最终报告,GPT-5-mini 回溯插入行内引用。
关键设计:session-level 训练——把完整轨迹按 Context Condenser 的压缩边界切成多个 session,每个 session 只包含当前有效上下文,解耦训练长度与轨迹长度。
三阶段数据规模(论文 Table)
#Session = 轨迹按 Context Condenser 切分后的 SFT 训练样本数(平均每条 Traj. 约 2 个 Session)。MT 是独立辅助任务,无 Session 概念;RL 只用任务 prompt,不存轨迹。
| Stage | Type | #Task | #Traj. | #Session |
|---|---|---|---|---|
| MT | ||||
| C.S.(上下文摘要) | — | 309,346 | — | |
| R.I.E.(信息提取) | — | 1,052,663 | — | |
| SFT | ||||
| Objective | 5,070 | 19,435 | 39,861 | |
| Open-ended | 1,958 | 4,485 | 11,903 | |
| RL | ||||
| Objective | 864 | — | — | |
| Open-ended | 269 | — | — | |
阶段 3:Reinforcement Learning(RL)
用 GRPO 做 outcome-based RL,复合奖励函数:
- s_rubric:Rubric Tree 评估分数。客观任务直接用;开放任务将成对分数映射为离散奖励等级
- s_fact:引用事实核查分数——提取行内引用,检索网页,LLM 判断 supported / unsupported 比例
- min 操作:防止「引用正确但内容全错」获得虚高奖励
论文踩过的坑:为什么开放任务要那样评分?
QUEST 的不少设计来自试错——尤其是开放任务的 reward 信号,论文专门用一节(§7.4)讲了两种失败方案,才收敛到前文提到的相对成对评分。
- Judge 对每个 rubric 节点打 0 / 0.5 / 1 三档
- 没有参照物——只评候选报告,不和任何 baseline 比
- 结果:约 50% 的样本总分接近 1.0,好坏报告拉不开差距(高分膨胀)
- 原因:Judge 没有对比基准时,倾向于给「面子分」
- 用教师模型生成参考报告,Judge 判候选是赢/平/输 → 映射为 1 / 0.5 / 0
- 有参照物了,但早期学生模型全面弱于教师
- 结果:几乎所有样本都被判「输」→ 分数坍缩到 0,SFT 筛选和 RL 都没信号可用
- 原因:二元胜负太粗,弱模型永远拿不到正反馈
- 仍用 $G_{\mathrm{syn}}$ 合成参考报告 $r_{\mathrm{ref}}$ 作为质量锚点
- Judge 同时看到候选报告和参考报告,对每个 rubric 节点分别打 0–10 连续分
- 分别沿 Rubric Tree 聚合得 $J(\mathrm{cand})$ 和 $J(\mathrm{ref})$,再算相对分:$\mathrm{Score} = J(\mathrm{cand}) / (J(\mathrm{cand}) + J(\mathrm{ref}))$
- 好处:候选比参考好 → Score > 0.5;差 → < 0.5;不会因为弱于教师就全是 0,也不会没有参照就全给高分
直觉上:方案 A 是「没有尺子瞎打分」,方案 B 是「和奥运冠军比输赢——新手永远输」,最终方案是「和参考报告比相对质量——有进步就能拿分」。
Mid-Training 和 RL 里试过的其他方向
以下设计在论文中有实验,但最终没有进入 QUEST 主配方。
实验结论
QUEST-35B 在 8 个深度研究 benchmark 上建立了开源 Agent 的新 SOTA,多个指标匹配或超越闭源前沿系统。
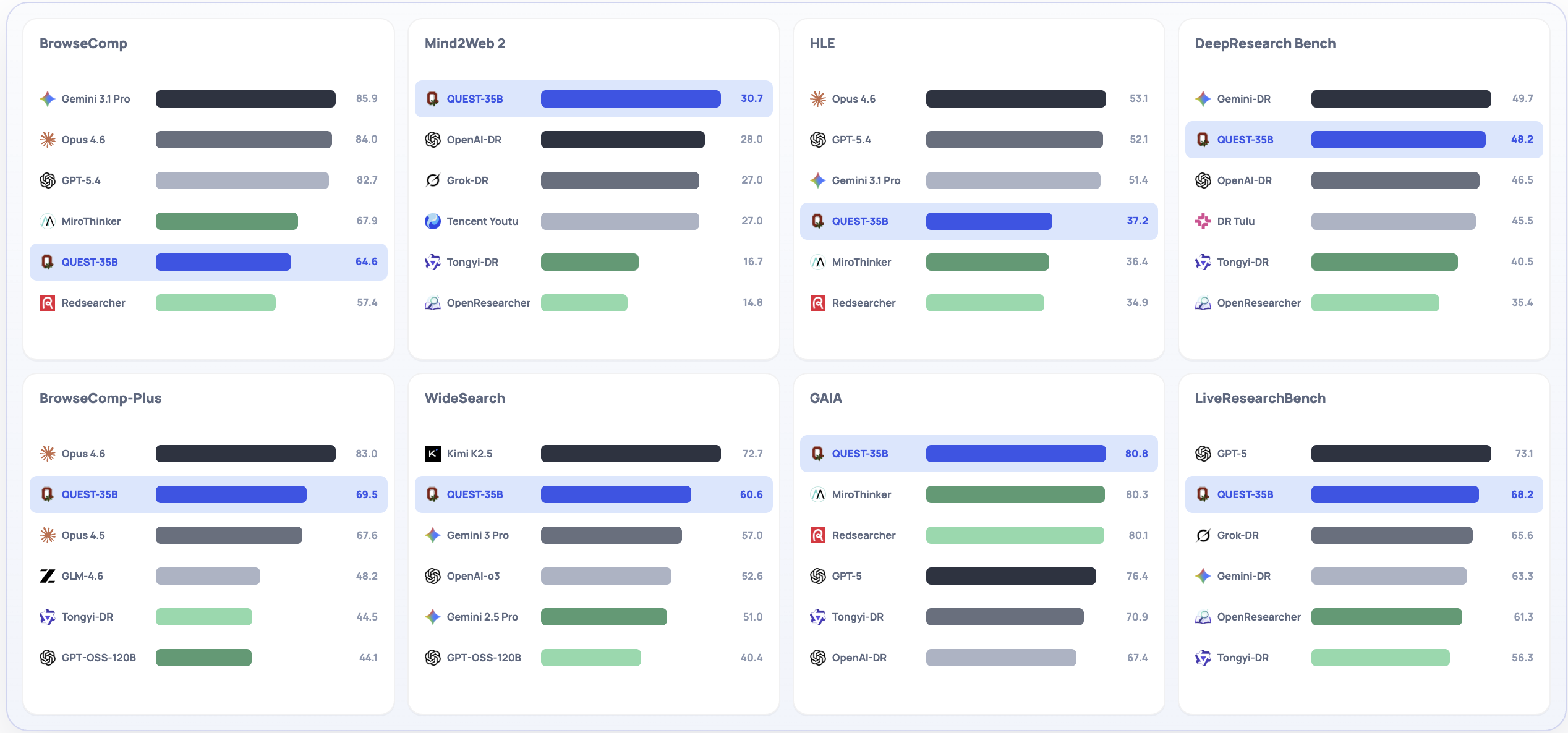
QUEST-35B 与主流闭源 / 开源深度研究 Agent 在 8 个 benchmark 上的整体对比。
展开说明 ▸- 客观任务:BrowseComp、BrowseComp-Plus、Mind2Web 2、WideSearch、HLE、GAIA
- 开放任务:DeepResearch Bench (DRB)、LiveResearchBench (LRB)
- QUEST-35B 在 M2W2 (30.7% vs 28.0%) 和 DRB (48.2% vs 47.0%) 上超越 OpenAI-DR
- 在 GAIA 文本子集 (80.8% vs 76.4%) 上超越 GPT-5
- 同规模对比中,QUEST-30B 在 8 个 benchmark 中 4 个最优,覆盖引用和报告综合类任务
(discard-all 策略)
超越 OpenAI-DR
开源 SOTA
消融与规模实验的关键发现
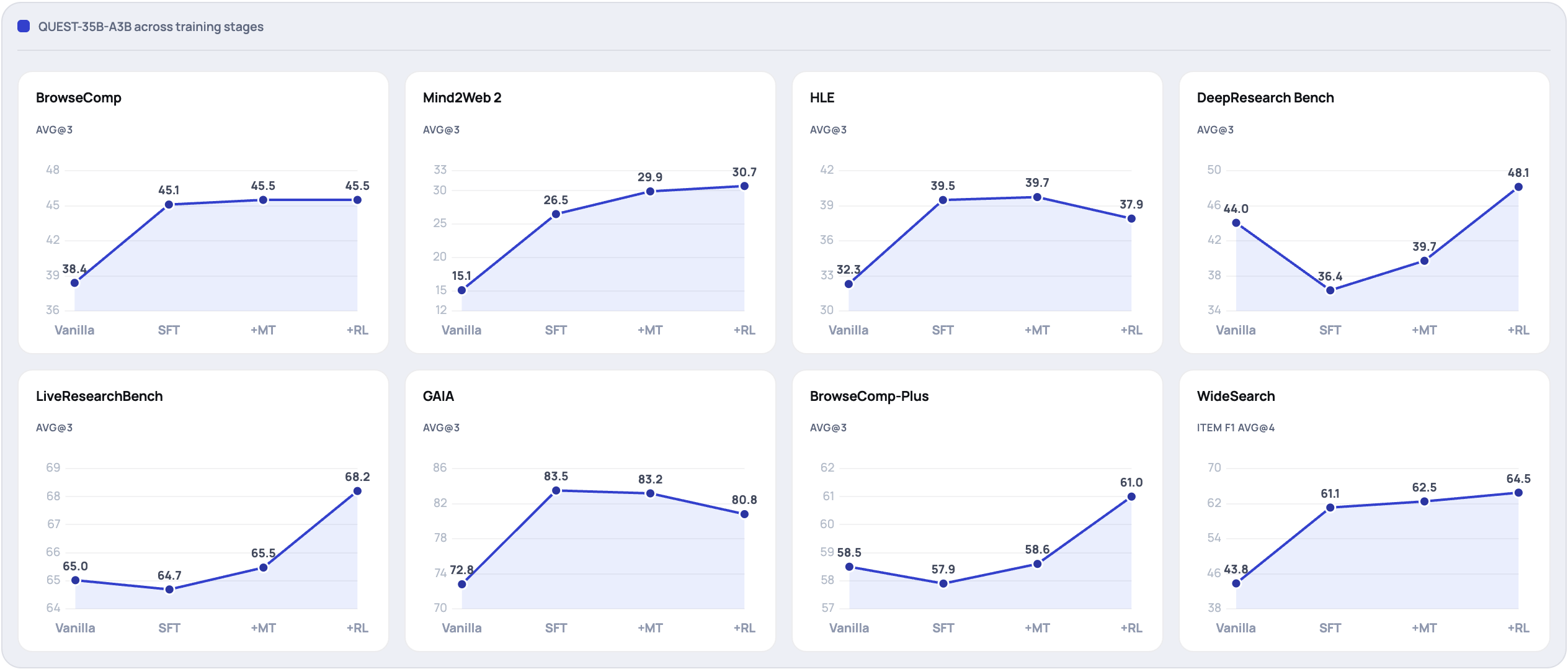
图 5:QUEST-35B 在四个训练阶段(Vanilla → SFT → +MT → +RL)上八个 benchmark 的分数变化。所有结果均使用 context condenser。
展开说明 ▸- SFT:多数客观 benchmark 大幅提升(WideSearch 43.8→61.1,GAIA 72.8→83.5);但 DeepResearch Bench 从 44.1 降到 36.4——开放报告合成受损
- +MT:在 SFT 基础上普遍小幅回升;DRB 从 36.4 恢复到 39.7,M2W2 从 26.5 到 29.9
- +RL:开放任务爆发——DRB 39.7→48.2,LRB 65.5→68.2;但 HLE(39.7→37.9)和 GAIA(83.2→80.8)略降,论文归因于 alignment tax
- 读图要点:没有单一阶段在所有 benchmark 上最优;MT+SFT+RL 组合在开放 + 客观任务间最均衡
- 三阶段缺一不可:纯 SFT 提升客观任务但损害开放任务;RL 大幅提升开放任务但略牺牲 HLE/GAIA 的专家级推理(类似 alignment tax)
- 小模型出人意料地强:QUEST-2B-SFT 在 HLE (30.3) 和 GAIA (72.8) 上已具竞争力,适合隐私敏感场景的本地部署
- 报告综合仍是小模型短板:2B 在 DeepResearch Bench 上远落后,说明开放报告合成比事实检索更难规模化迁移
- 能力覆盖 > 参数量:不同数据配方决定能力偏向;QUEST 配方在三大能力上最均衡
「仅 8K 合成任务,QUEST 就接近甚至超越了闭源前沿 Agent——关键在于 Rubric Tree 提供了可验证的细粒度训练信号,而非数据规模。」