30 秒速览
把任意模态变成 token,本质是回答两个问题:怎么把连续信号切成有限个单元,以及每个单元用什么形式表示。
- 切块:图像切成 patch、视频切成时空 tubelet、音频切成时间帧——连续信号先被切成一串有限的小块。
- 软 token(连续向量):每个块过编码器得到一个实数向量,再用 projector 投影到 LLM 空间。模型能「看懂/听懂」,但不能自回归「说出」它。用于理解。
- 硬 token(离散 id):用一个 codebook(码本)把向量量化成整数 id,跟文本 token 一模一样,并进词表。模型能像写字一样「生成」图像/音频。用于生成。
- 一句话:理解走「编码器 + 投影」,生成走「量化成离散码」。剩下的全是怎么切得省、量化得准的工程细节。
为什么非要「打成 token」不可
一个 Transformer 大模型的输入,永远是一串向量:序列里的每一项都是一个 $d$ 维向量,模型在这些向量之间做注意力。文本之所以好处理,是因为它天生就能切成离散单元:
文本的 token 是怎么来的(基准参照)
先用 BPE 切成子词,每个子词查词表得到一个 id,id 再查 embedding 表得到向量
→
切块 (BPE)
token / ization
切成子词
→
→
查 embedding
[向量, 向量]
喂给 Transformer
文本的关键便利在于:它本来就是离散符号,词表是有限的(几万个),切块规则(BPE)也现成。但图像、视频、音频是连续信号——一张图是上百万个像素的实数,一秒音频是上万个采样点,没有天然的「词」,也没有有限词表。
所以多模态 tokenization 要补上文本天生就有的两样东西:
- 怎么切:把连续信号切成有限个、数量可控的单元(否则序列长到注意力算不动)。
- 每个单元表示成什么:是直接用一个连续向量(软 token),还是逼它变成「有限词表里的一个 id」(硬 token)。
这第二个选择是整篇文章的分水岭:它直接决定了模型只能读懂这个模态,还是也能生成这个模态。下一节把这个框架画出来。
统一框架:切块 + 量化,两条路线
不管什么模态,整条流水线都长一个样:连续信号 → 切块 → 编码 → (选择性量化)→ token 序列 → Transformer。唯一真正分叉的地方,是中间那个「要不要量化成离散 id」。
所有模态共用的一张图
三种模态先被切块编码,然后在「软 / 硬」处分叉,最后汇入同一个 Transformer
软 token vs 硬 token:唯一需要先记牢的对比
这两个词后面会反复出现。它们不是两种「模态」,而是同一个连续向量的两种命运:
软 token 连续 · 理解
编码器输出的连续实数向量,不查任何词表,直接经一个 projector(线性层或 MLP)对齐到 LLM 的输入空间,拼在文本 token 旁边。
- 信息几乎无损,细节保留好
- 但它不在「有限词表」里,softmax 无法预测它 → 模型读得懂,却生成不出
- 代表:LLaVA、Qwen-VL、Whisper 接 LLM
硬 token 离散 · 生成
把连续向量在一个 codebook 里找最近邻,替换成那个码字的整数 id。这一步「有损」,但换来了和文本完全一致的形态。
- 就是有限词表里的一个 id,可以并进 LLM 词表
- 模型能用 softmax 自回归预测下一个 token → 能生成图像 / 音频
- 代表:VQGAN(图)、EnCodec(音)、Chameleon / AnyGPT(统一)
记住这条因果链:想让模型「生成」某个模态 → 输出必须是离散 token → 必须做量化(codebook)。这就是为什么生成模型几乎都绕不开 VQ 系列方法。
图像:切成 patch,或量化成码字
图像是二维像素网格。切块的标准做法来自 ViT(Vision Transformer):把一张 224×224 的图切成不重叠的 16×16 小块,得到 14×14 = 196 个 patch,每个 patch 拉平后过一个线性层,变成一个 patch embedding。这一步把「图」变成了一串「图块向量」。
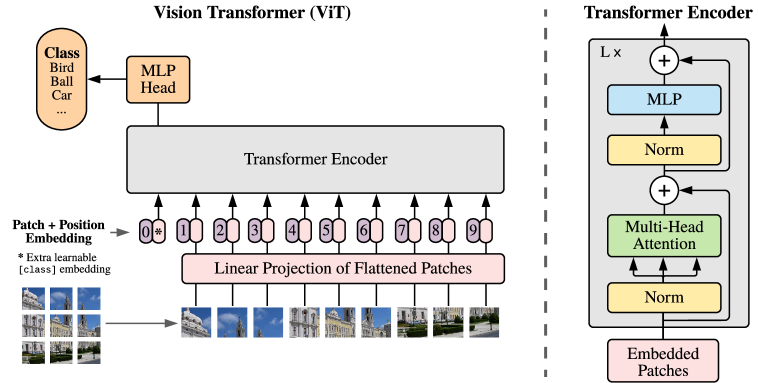
ViT 的切块总览:图像 → 固定大小 patch → 线性投影 + 位置编码 → 标准 Transformer Encoder。
来源:Dosovitskiy et al., ICLR'21, arXiv:2010.11929, Figure 1
展开说明 ▸
但注意:ViT 的 patch embedding 是连续向量(软 token)——适合理解,不能直接生成。要让模型「画」出一张图,需要把图变成离散 id,这就是 VQ-VAE / VQGAN 做的事。
VQ-VAE / VQGAN:给图像建一本「码本词典」
思路是先学一本 codebook(码本):里面有比如 8192 个「码字向量」,相当于图像世界的「词表」。流程是:
- 编码:CNN 把图压成一个小特征网格(如 16×16),每个格子是一个连续向量。
- 量化:每个格子向量在码本里找最近邻,替换成那个码字的整数 id。于是整张图 → 256 个离散 token(就像 256 个「字」)。
- 解码:decoder 学会从这串 id 还原出图像。VQGAN 在此基础上加了对抗损失(GAN)和感知损失,让重建更清晰。
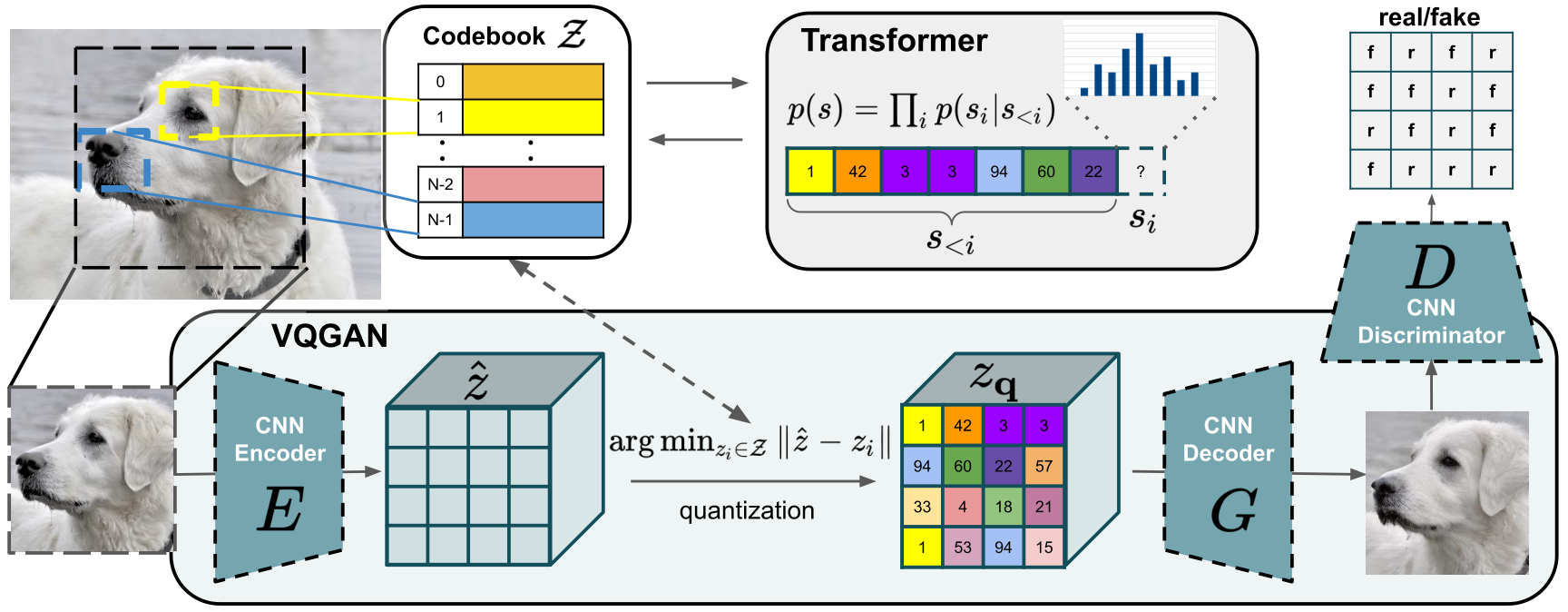
VQGAN:用 CNN + 码本把图像压成离散码字序列,再让 Transformer 像写文本一样自回归地生成这串码字。
来源:Esser et al., CVPR'21, "Taming Transformers"(VQGAN)项目图 assets/teaser.png
展开说明 ▸
ViT patch(软)理解
切块后不量化,保留连续向量。信息全、对齐语义易,但生成不出来。
VQ 码字(硬)生成
切块后量化成 id。有损压缩,但成了离散词表,能被自回归生成。
视频:图像 + 时间,再对付「token 爆炸」
视频就是「图像 + 时间轴」,所以切块多了一个时间维度。但真正的核心难题不是怎么切,而是切完之后 token 太多:一段 1 分钟、30fps 的视频有 1800 帧,每帧若按 ViT 切成几百个 patch,序列就长到几十万——注意力根本算不动。所以视频 tokenization 的主线是怎么在时空上压缩。两条典型思路:
视频切块的两种思路
左:逐帧切 patch 再在时间上合并;右:直接切「时空小块」tubelet
- 逐帧 + 合并:先采样若干关键帧,每帧用 ViT 切 patch,再把相邻 patch、相邻帧合并压缩 token 数——具体就是过一层 MLP 或卷积把相邻的几个 patch(如 2×2)聚合成一个 token(Qwen2-VL 等多模态理解模型常用)。
- 时空 tubelet:把视频当成一个三维立方体,直接切成「时间×高×宽」的小块(如 2×16×16),每个 tubelet 一个 token——把时间维度也一起 patch 化(ViViT、VideoMAE)。
视频生成同样可以走离散路线:用 3D 版的 VQ 模型(如 MAGVIT 的时空 tokenizer)把视频量化成离散码字序列,再交给 Transformer 自回归。本质和图像一致,只是码本与编码器都升级成处理时空块。
视频这一节真正要带走的不是某个模型,而是这个权衡:切得越细,信息越全但 token 越多;时空压缩则是在「画质/细节」和「序列长度」之间找平衡。
语音 / 音频:从波形到时间帧,再分语义与声学
音频是一维波形:16kHz 采样意味着每秒一万六千个数,直接当 token 序列会爆炸。所以第一步永远是压成时间帧——通常先转成 log-mel 频谱(每 10–25ms 一帧),或用卷积直接下采样。之后同样分软、硬两条路。
动手理解 log-mel:波形怎么变成一张「像图片」的频谱
点「下一步」:从一维波形,一步步走到 Whisper 眼中的二维 log-mel 频谱
能量低能量高
注意这个过程只是「换一种表示」,没有做量化:log-mel 频谱仍是连续实数。真正决定软/硬 token 的,是它之后是过编码器(软)还是过 codebook(硬)。
连续路线(理解):Whisper 这类做法
语音理解模型(如 Whisper,以及把语音接进 LLM 的方案)走软 token:log-mel 频谱过卷积 + Transformer 编码器,每约 20ms 输出一个连续向量。这些向量当软 token 喂给后续模型——能转写、能听懂,但本身不是离散符号。

Whisper:把音频转成 log-mel 频谱(连续的时间-频率图),过卷积下采样后送进 Transformer。这是音频的「软 token」路线。
来源:Radford et al., OpenAI Whisper, arXiv:2212.04356, 项目图 approach.png
展开说明 ▸
离散路线(生成):声学 token 与语义 token
要让模型「说话」「作曲」,音频也必须变成离散 token。这里有个语音领域特有的二分,务必分清:
声学 token(acoustic)保真
目标是高保真重建波形,连音色、环境声都留住。代表是 SoundStream / EnCodec,核心技术是 RVQ(残差向量量化)。
- 重建音质好,适合 TTS、音乐生成
- 每帧需要多个码本(多个 token),序列偏长
语义 token(semantic)内容
目标是抓说了什么(接近音素/语义),丢掉音色细节。代表是 HuBERT / wav2vec 2.0:把自监督模型中间层特征做 k-means 聚类,每帧落到一个簇 id。
- 更贴近语言、利于语音理解与建模
- 单独还原音质差(丢了声学细节)
现代语音大模型(如 SpeechTokenizer、AudioLM)往往两者结合:语义 token 负责「说什么」,声学 token 负责「怎么发声」,兼顾内容与音质。
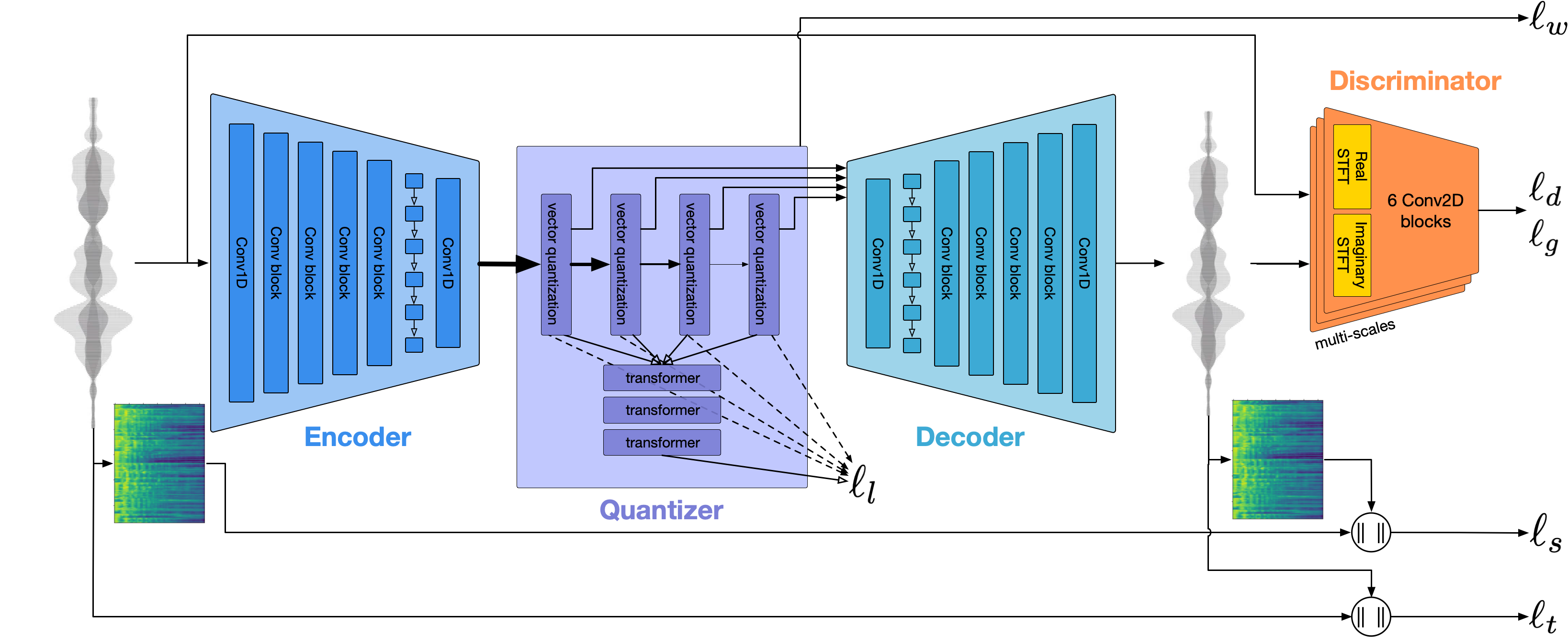
EnCodec:卷积编码器把波形压成帧向量,经 RVQ 量化成多层离散码,再由解码器重建波形。
来源:Défossez et al., Meta, "High Fidelity Neural Audio Compression",arXiv:2210.13438,项目图 architecture.png
展开说明 ▸
动手理解 RVQ:残差怎么一层层被「吃掉」
点「下一层量化」:每加一个码本,重建(红)就更贴近目标(灰),误差下降,token 序列变长
还没开始量化。整帧的信息都在「残差」里(残差 = 目标本身)。点下面的按钮开始第一层量化。
为什么音频 token 是「多码本」的?因为单个码本量化误差太大、还原不了音质,RVQ 用「残差再量化」逐层逼近——代价就是每个时间帧对应多个 token,这也是音频序列普遍比文本长的原因。
最后一步:token 怎么真正进到 LLM 里
有了 token,还要让它和文本在同一个模型里共处。这里又回到那条分水岭——你是只要理解,还是也要生成,决定了两种截然不同的接法。
两种接法
上:理解 = 软 token 经 projector 拼到文本前;下:生成 = 硬 token 并进统一词表
理解:软 token 拼到文本旁边
编码器(ViT、Whisper)输出连续向量,经一个 projector(线性层或小 MLP)把维度和语义空间对齐到 LLM 的输入,然后像「占位 token」一样插在文本 token 序列里。训练时常冻结编码器,主要训 projector 和 LLM。代表是 LLaVA、Qwen-VL 这类「看图说话」模型——它们能理解图像,但输出始终是文本。
生成:把多模态码本并进词表
要生成图像/音频,就把视觉/音频 codebook 的 id 追加到文本词表后面,组成一个统一的大词表。模型在这个词表上自回归——它「写」出的可能是一个文字 id,也可能是一个图像码字 id。生成完的图像 token 再送回 VQ decoder 还原成像素。代表是 Chameleon(图文 early-fusion 统一建模)、AnyGPT(文/图/语音/音乐统一离散 token)、VALL-E(把 TTS 当成语音 token 的语言建模)。
把这句话刻在脑子里:「理解」可以用连续软 token 偷懒,但「生成」逼着你把模态压成离散硬 token——因为 LLM 只会在一个有限词表上做 softmax。
一张表收束全部
| 模态 |
怎么切块 |
软 token(理解) |
硬 token(生成) |
| 文本 |
BPE 子词切分 |
天生离散,本身就是词表 id(无需软/硬之分) |
| 图像 |
切 16×16 patch(ViT) |
patch embedding(LLaVA / Qwen-VL) |
VQ-VAE / VQGAN 码字 id |
| 视频 |
逐帧 patch + 合并,或时空 tubelet |
压缩后的帧 / tubelet 向量 |
3D-VQ(如 MAGVIT)时空码字 |
| 语音 / 音频 |
log-mel 频谱 / 卷积下采样成时间帧 |
Whisper 帧向量 |
声学 token(EnCodec/RVQ)+ 语义 token(HuBERT) |
读完应该带走的三句话
- 切块是共性:所有模态都先被切成有限个单元(patch / tubelet / 帧),这一步让连续信号变得「可数」。
- 软 / 硬是分水岭:要不要量化成离散 id,取决于你只想理解,还是要生成。这是唯一真正分叉的设计决策。
- 剩下都是工程:怎么切得省(视频压缩)、怎么量化得准(RVQ 多码本)、怎么兼顾内容与音质(语义 + 声学 token)——都是在「序列长度 vs 信息保真」之间做权衡。
所以下次看到某个新多模态模型,只问三件事:它怎么切块?它用软 token 还是硬 token?如果是硬 token,码本怎么设计? 答完这三问,它的 tokenization 你就懂了。