EAGLE-3:用 Training-Time Test 让 LLM 推理加速 Scaling Up
EAGLE 系列通过「先猜后验」加速 LLM 推理,但旧版 EAGLE 的草稿模型受限于 feature 预测约束,堆再多训练数据也不涨点。 EAGLE-3 做了两个关键改动:放弃 feature 预测、改为直接预测 token(配合 training-time test 解决训练-推理分布不一致),以及用多层特征融合替代仅用顶层特征。 这让草稿模型第一次展现出推理加速领域的 scaling law——数据越多,加速比越高,最高可达 6.5x。
(Vicuna 13B · HumanEval · T=0)
(batch size = 1)
(batch size = 64 · H100)
已有方案速览
在进入 EAGLE 系列之前,先了解 speculative sampling 领域的几条主要技术路线——它们的做法和局限,是理解 EAGLE 系列设计动机的前提。

EAGLE 系列演变:从 feature 自回归到 scaling law
理解 EAGLE-3 的设计动机,需要先看 EAGLE 系列三代分别在解决什么问题。每一代都站在上一代暴露的瓶颈之上。
EAGLE(ICML 2024):在 feature 层做自回归
传统 speculative sampling 用独立的小 LLM 当草稿模型,小模型和大模型之间的分布差距决定了加速比天花板。EAGLE 的核心洞察是:与其用独立小模型去猜 token,不如直接借用目标模型的中间特征。具体来说,EAGLE 复用目标模型 LM head 之前的顶层特征(second-to-top-layer),在 feature 层面做自回归预测,然后用目标模型的 LM head 把 feature 转成 token 分布。
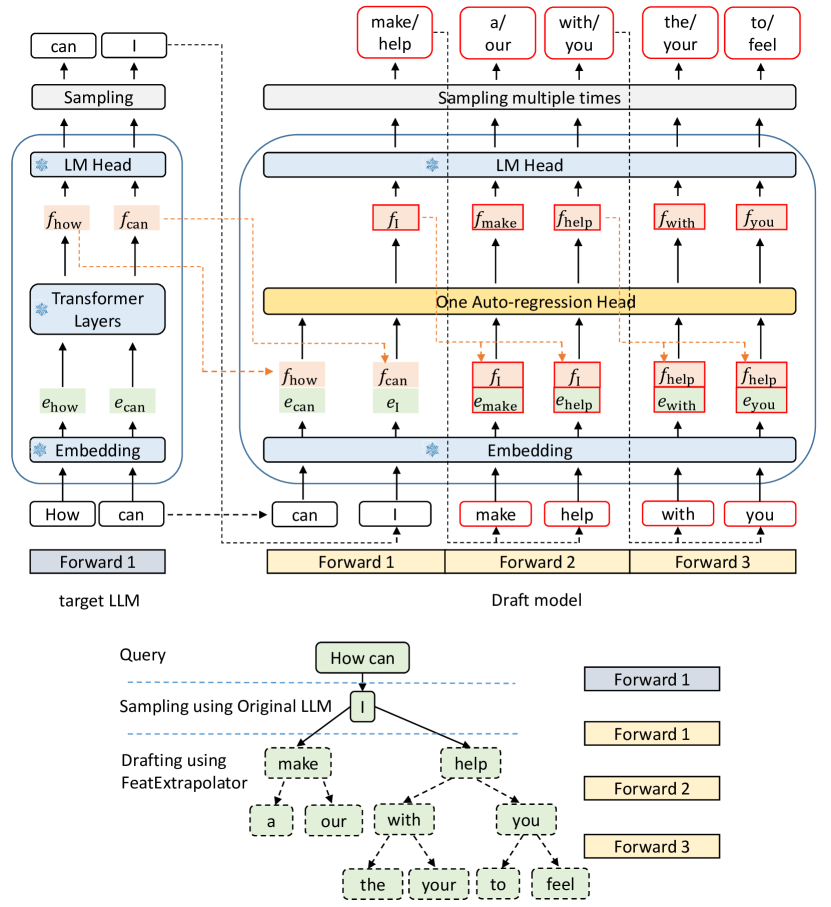
但 feature 层自回归面临一个独特的挑战:采样过程引入的不确定性。如下图所示,token「I」之后可能是「always」也可能是「am」——这两种情况对应完全不同的 feature 序列。仅靠 feature 序列无法知道采样结果,导致预测不准。EAGLE 的解决办法是额外输入一个前移一步的 token 序列(即上一步的采样结果),消除不确定性。

下图展示了 EAGLE 与其他方法在草稿生成阶段的对比:标准 speculative sampling 和 Lookahead 在 token 层面预测;Medusa 用多个独立解码头从 feature 并行预测多个位置的 token;而 EAGLE 在 feature 层自回归,同时输入 feature 和前移 token 序列。
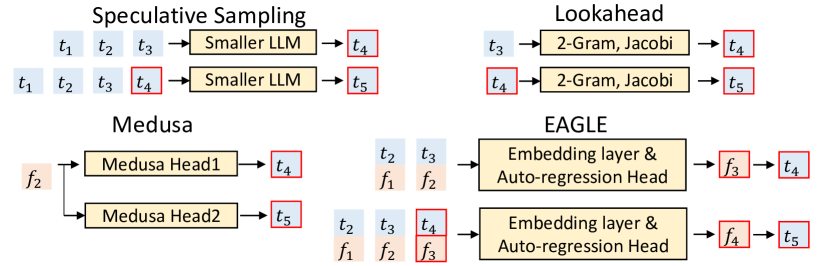
完整的 EAGLE 管线如下:草稿模型由 Embedding 层、FC 降维层、单层 Decoder 和目标模型的 LM Head 组成。Feature 序列和前移 token embedding 拼接后降维,经 Decoder 预测下一个 feature,再由 LM Head 转成 token。整个过程用树状结构生成草稿,tree attention 并行验证。
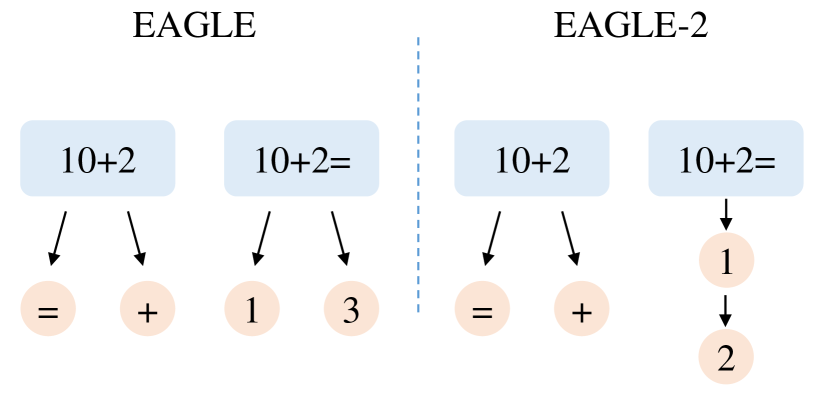
EAGLE-2(EMNLP 2024):动态草稿树
EAGLE 和 Medusa 使用的是静态草稿树——不管上下文难不难,树的形状都一样。但现实中不同位置的预测难度差异很大:有的 token 几乎必中(如「10+2=」后面跟「1」),有的 token 很难猜。静态树对简单位置浪费了节点,对困难位置又分配不够。
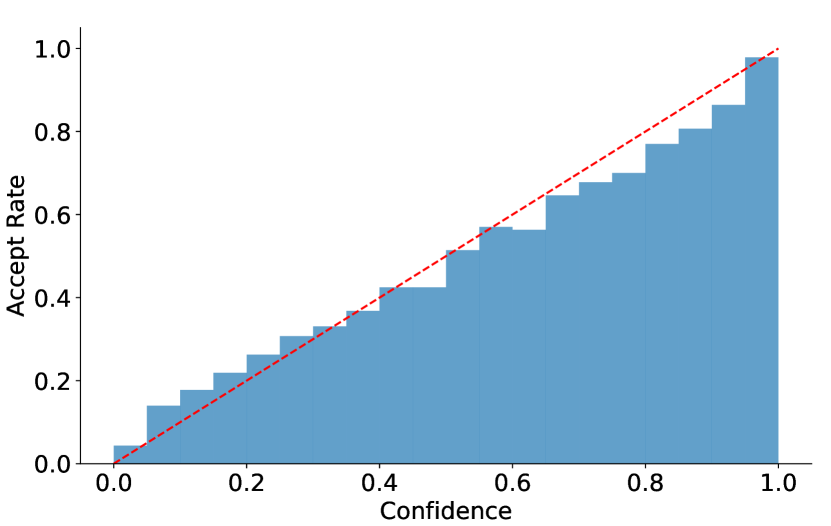
EAGLE-2 的关键发现是:草稿模型的置信度(输出概率)与实际接受率高度正相关。下图展示了这种校准性——置信度低于 0.05 的 token 接受率约 0.04,置信度高于 0.95 的接受率约 0.98。这意味着可以用置信度实时估计每个候选的接受概率,据此动态调整草稿树结构。
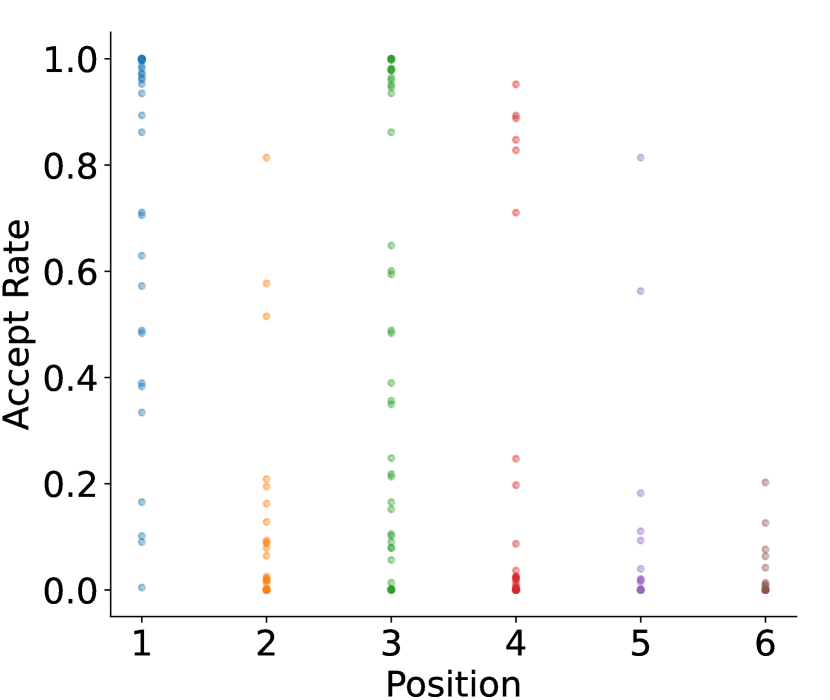
光看校准性还不够——如果所有上下文的接受率差不多,静态树也够用了。下图直接展示了问题所在:在草稿树的 6 个位置(P1 靠近树根,P6 靠近树叶),每个 query 的接受率用一个点表示。可以看到同一位置的接受率方差极大(P1 位置的点从 0.2 分布到 1.0),说明草稿难度不仅取决于位置,更取决于当前上下文。这就是动态草稿树的必要性:同一位置,简单 query 只需 1 个候选,困难 query 可能需要 5 个。
EAGLE-3(2025):打破 scaling 瓶颈
EAGLE-2 在草稿树调度上做到了极致,但草稿模型本身的架构没变——仍然是 feature 层自回归 + 顶层特征。当作者尝试用更多数据训练草稿模型时,发现加速比几乎不涨(见下方 scaling 曲线图)。EAGLE-3 的两个改动正是为了打破这个瓶颈,后面会详细展开。
为什么需要 EAGLE-3
LLM 的自回归生成是串行的——每生成一个 token 都要跑一遍全部参数。Speculative sampling(投机采样)通过「小模型先猜、大模型并行验」来部分并行化生成,显著降低延迟。EAGLE 系列是其中效果最好的方案之一:它不用独立的小 LLM 当草稿模型,而是复用目标模型的顶层特征,在 feature 层面做自回归。
但当作者尝试用更多数据训练 EAGLE 的草稿模型时,发现了一个令人意外的现象:数据量翻 8 倍,加速比几乎不涨。问题出在哪?

EAGLE 的 feature 预测约束
EAGLE 的草稿模型训练有两个 loss:feature 预测 loss(Smooth L1,让输出逼近目标模型的顶层特征 f)和 token 预测 loss(Cross Entropy)。Feature 预测 loss 让草稿模型在训练时只看第 1 步就能泛化到多步推理,但同时也构成了一个额外约束——草稿模型只有 1 层 Decoder,容量非常有限,而 feature loss 迫使模型把大量容量花在几何拟合上(让输出向量在空间中接近目标模型的 feature),而不是花在「怎么预测 token 最准」这个最终目标上。
这就是 scaling 失效的根本原因:数据变多能帮助模型学到更丰富的 token 预测模式,但如果输出空间被 feature loss 锁死在目标模型的特征空间里,多出来的数据只能帮模型把 f̂ 拟合得更像 f——这件事本身已经接近极限了。Feature 预测是一个过强的正则化:数据少时帮助泛化,数据多时变成枷锁。
此外,feature 预测约束还间接锁定了输入端:草稿模型必须用顶层特征做输入(否则 feature loss 没有意义)。而顶层特征和 next-token logits 是一一对应的(LM head 全秩),信息高度特化于下一个 token 的预测。去掉 feature 约束后,输入端也获得了自由度——可以改用多层融合特征,获取更丰富的上下文信息。
EAGLE-3 的核心创新
EAGLE-3 的改进可以拆成两个互相配合的设计决策。两者缺一不可——光做其中一个都会遇到问题。
创新一:放弃 feature 预测,用 Training-Time Test 做直接 token 预测
EAGLE 的草稿模型要同时满足两个目标:在几何上拟合目标模型的 feature(Smooth L1 loss)、在语义上预测对 token(Cross Entropy loss)。EAGLE-3 的核心洞察是:feature 预测是手段,不是目的——它的作用只是让单步训练能泛化到多步推理,但代价是过度约束了草稿模型的输出空间,挤占了有限的模型容量。如果能找到另一种方式保证多步泛化能力,这个约束就可以丢掉,释放全部容量给 token 预测。
但直接丢掉 feature 预测会出问题。下图中间的方案展示了这种情况:去掉 feature 约束后,第 1 步的接受率(0-α)确实大幅提升,但草稿模型输出的向量 a 与真实 feature f 差距很大,导致第 2 步输入偏离训练分布,接受率(1-α)暴跌。

解决方案就是 Training-Time Test:在训练时模拟推理过程。第 1 步正常前向,得到输出 a;然后把 a 喂回草稿模型做第 2 步、第 3 步……每一步都计算 token 预测 loss。这样草稿模型在训练时就学会了处理「自身输出作为输入」的场景,推理时不再出现分布偏移。


创新二:多层特征融合替代顶层特征
去掉 feature 预测约束后,草稿模型的输入不再被锁定在顶层特征上——它可以自由选择使用目标模型的哪些信息。EAGLE-3 利用这个自由度,将目标模型的低层、中层、高层特征拼接后通过 FC 层融合为一个向量 g。
- 被 feature loss 锁定,只能用顶层特征
- 信息高度特化于 next-token,上下文多样性有限
- 模型容量被 feature 拟合挤占
- 低层 → 表面语法 / 词法信息
- 中层 → 句法 / 局部语义
- 高层 → 全局语义 / 推理信息
- 融合后信息更丰富,利于多步预测
消融实验:两个改进各贡献多少
| 方法 | MT-bench 加速比 | MT-bench τ | GSM8K 加速比 | GSM8K τ |
|---|---|---|---|---|
| EAGLE-2(基线) | 3.16x | 4.05 | 3.39x | 4.24 |
| + 去掉 feature 约束 | 3.82x | 5.37 | 3.77x | 5.22 |
| + 多层融合(EAGLE-3) | 4.40x | 6.13 | 4.48x | 6.23 |
两个改进各自贡献显著:去掉 feature 约束让加速比从 3.16x 跳到 3.82x,再加上多层融合进一步提升到 4.40x。
EAGLE-3 推理管线详解
和其他 speculative sampling 方法一样,EAGLE-3 在「草稿生成」和「验证」之间交替。以下以「How can I do it」为例,展示草稿生成的三步过程。

特征融合 + 第一步草稿
目标模型对前缀「How can」做前向,生成 token「I」。同时记录低/中/高层特征 l、m、h,拼接后过 FC 层得到融合特征 g。将 g 与采样结果「I」的 embedding 拼接,输入单层 Decoder,得到输出 a。a 过 LM head 采样得到草稿 token「do」。
用自身输出替代缺失特征
第 2 步需要「I」的融合特征 gI,但「I」尚未被目标模型验证,无法获取真实特征。于是用上一步的输出 aI 替代 gI,与「do」的 embedding 拼接后输入 Decoder,采样得到「it」。
持续自回归
同理,第 3 步用 ado 替代 gdo,与 eit 拼接输入 Decoder。后续步骤以此类推。最终生成的树状草稿送给目标模型并行验证。
训练时的 Attention Mask 设计
Training-time test 需要在训练时模拟多步推理。关键技巧在于 attention mask 的设计:第 1 步(原始训练数据)用标准下三角 mask;第 2 步起,草稿模型的输出与原始序列形成树状依赖关系,attention mask 变成对角阵(每个预测 token 只看自己对应的父节点),只在与原始训练数据交互时保持因果关系。实现上用向量点积替代矩阵乘法,避免计算浪费。
推理加速领域的 Scaling Law
这是 EAGLE-3 最令人兴奋的发现:在新架构下,草稿模型的训练数据量和加速比之间呈现出清晰的 scaling law。这在之前的 speculative sampling 方法中从未被观察到。
原因很直观:去掉 feature 预测约束后,草稿模型的输出空间不再被锁死在目标模型的特征空间里,全部容量都释放给 token 预测。数据越多,模型能学到越丰富的 token 预测模式——而不是像以前那样,多出来的数据只能把 feature 拟合得更精确(一件收益递减的事)。容量释放 + 数据充足,scaling 自然生效。
作者用了约 8 倍于 EAGLE 的训练数据(ShareGPT + UltraChat-200K,约 53 万条数据),且为推理模型 DeepSeek-R1-Distill-LLaMA 8B 额外加入了 OpenThoughts-114k-math 数据集。他们预期更大的数据量还能带来进一步的提升。

实验结论
EAGLE-3 在 4 个目标模型(Vicuna 13B、LLaMA-Instruct 3.1 8B、LLaMA-Instruct 3.3 70B、DeepSeek-R1-Distill-LLaMA 8B)× 5 个任务上全面领先。几个关键数字:
(T=0,5 个任务)
(Vicuna 13B · HumanEval)
(SGLang + H100 · bs=1)
生产级框架中的大 batch 吞吐
Speculative sampling 通常被认为在大 batch 下会降低吞吐(因为计算冗余减少)。EAGLE 在 SGLang 中 batch=24 时吞吐已低于基线,而 EAGLE-3 得益于更高的接受率,在 batch=64 时仍有 38% 的吞吐提升。
| 方法 | bs=2 | bs=8 | bs=16 | bs=32 | bs=64 |
|---|---|---|---|---|---|
| EAGLE (SGLang) | 1.40x | 1.23x | 1.02x | 0.94x | 0.99x |
| EAGLE-3 (SGLang) | 1.81x | 1.62x | 1.48x | 1.32x | 1.38x |
与 HASS 的区别
HASS 也在训练时模拟多步推理,但其动机和做法不同:HASS 仍然做 feature 预测、仍然依赖顶层特征,目的是缓解 EAGLE 的误差累积问题。而 EAGLE-3 从根本上放弃了 feature 预测,输入自由选择多层融合特征,表达能力更强。实验中 EAGLE-3 的加速比显著优于 HASS。