借鉴 Externalization in LLM Agents (2026) 对 Agent Memory 的分类方式,根据记忆内容将 Agent Memory 分为以下三块:
工作上下文
Agent 当前能看到的环境状态切片。
情节经验
从历史轨迹中提炼的可复用知识。
个性化记忆
特定用户的偏好、习惯、隐私约束。
一、工作上下文
LLM 的上下文与其表现高度相关,模型表现往往随着上下文长度的增加而下降。因此这一块的核心问题是:怎么让模型只看到信息量最多的那一部分信息。
观察什么:为 Agent 设计状态接口
原始的 bash CLI 指令往往带有大量无关信息,SWE-agent 针对处理 issue 这个场景,设计了一套定制化工具接口,让模型不被噪音塞满上下文。
历史压缩:上下文线性增长怎么办
上下文窗口是有限的,压缩是所有多轮 Agent 都需要有的设计。这里介绍经典论文 MemGPT 的设计和 Claude Code 的策略。
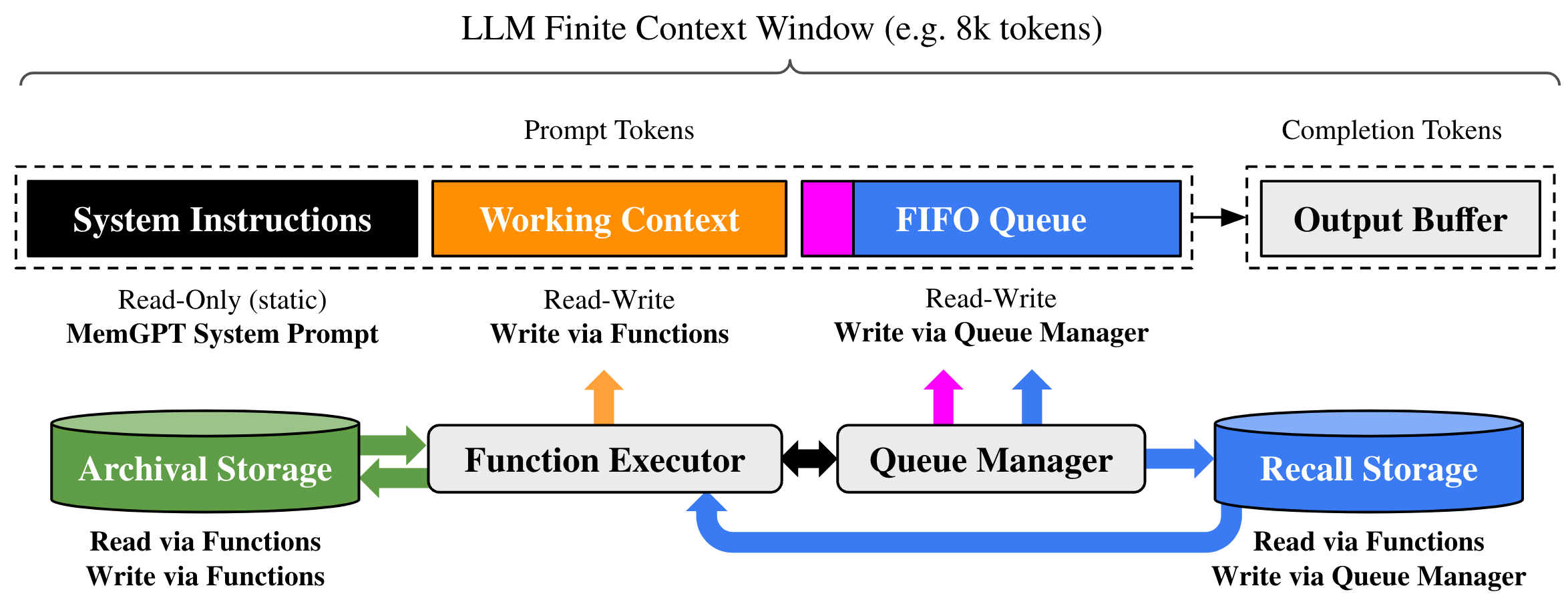
MemGPT 分层内存架构:Main Context(类比 RAM)分为 System Instructions + Working Context + FIFO Queue;External Context(类比 Disk)包含 Archival Storage 和 Recall Storage。
展开说明 ▸
- Main Context 三区:System Instructions(固定不驱逐)+ Working Context(可编辑 scratchpad)+ FIFO Queue(先进先出消息队列)。
- External Context 两库:Archival Storage(向量检索的事实库)+ Recall Storage(按时间检索的完整对话历史)。
- 自主 page-in/page-out:LLM 通过 function calls 自行决定何时存档、何时召回,窗口满时自动驱逐 + 递归摘要。
MemGPT 工程细节补充
- archival_memory_search 是向量检索:embedding 使用
text-embedding-ada-002,底层基于 pgvector 做 cosine similarity 搜索,返回最相关的文档片段。 - Archival Storage 写入依赖模型主动调用:LLM 通过
archival_memory_insertfunction call 决定存什么;memory pressure 警告会暗示模型保存信息,但最终是否存档完全由 LLM 自主决策。 - conversation_search 返回原始完整消息:结果是 role + content + timestamp 的原始记录(非摘要),默认返回约 5-10 条匹配消息。
- Recall Storage 支持两种检索模式:原始版本仅支持关键词匹配(substring match on message content);当前版本升级为 hybrid search,结合关键词匹配 + embedding 向量检索。
两个向量库:
- FIFO 压缩并将原文存到向量库 Recall Storage,允许模型通过工具调用复原。
- 模型可主动写入和读取(向量检索)的 Archival Storage。
FIFO Queue 驱逐机制
Main Context · FIFO Queue3/6
📋 Summary: msg1‑3 递归摘要
msg1你好!
msg2我是 AI 助手。
msg3能记住对话吗?
msg4在上下文内可以。
msg5太长了怎么办?
msg6触发记忆驱逐。
msg7新问题来了
── context window limit(6 slots)──
Recall Storage 💾
msg1你好!
msg2我是 AI 助手。
msg3能记住对话吗?
暂无驱逐消息
初始 · 0/5
队列中有 3 条消息(msg1, msg2, msg3),容量 3/6,一切正常。
MemGPT vs Claude Code /compact 对比
| 维度 | MemGPT (Packer 2023) | Claude Code /compact |
|---|---|---|
| 压缩触发 | FIFO 队列达 ~70% 发警告,100% 自动驱逐 | 上下文达 ~83.5% 自动触发;也可手动 /compact |
| 压缩方式 | 驱逐最旧 ~50% 消息 → LLM 递归摘要放在队首 | 分级裁剪:工具输出预算 → Microcompact → Auto-Compact(LLM 摘要) |
| 能否复原 | ✅ 原始消息完整存入 Recall Storage,可按需召回 | ❌ 不可逆,原始 token 丢弃 |
| 召回方式 | LLM 自主调 conversation_search / archival_memory_search | 无主动召回;依赖摘要质量 + CLAUDE.md 手动持久化 |
| 跨会话持久化 | ✅ 两库均跨会话保持 | ❌ 会话结束丢失(除非写入 CLAUDE.md) |
由于 MemGPT 保存了完整的上下文且可以自主召回,因此压缩策略更激进;Claude Code 为了任务完成度保留了很多信息,主要策略是优先丢弃工具返回,保留任务进度和用户意图。
查看对比:同一段对话,两种压缩 prompt 各自要求保留什么
假设原始对话包含:用户说「帮我重构 src/utils.py 的 parse 函数,要求兼容 Python 3.8」→ Agent 读了文件 → 改了代码 → 跑了测试 → 报错 → 修了 bug → 测试通过。
MemGPT 的摘要 prompt(早期 V1 风格):
「请将以下对话压缩为 100 词以内的摘要,保留关键信息。」
→ 输出:「用户要求重构 utils.py 的 parse 函数兼容 3.8。过程中遇到类型注解兼容问题,已修复。测试通过。」
→ 原文全部存入 Recall Storage,随时可通过 conversation_search 按关键词调回。Claude Code 的摘要 prompt(9 段式结构化):
要求生成的摘要必须覆盖:
1. Intent: 用户要求重构 src/utils.py 的 parse 函数,兼容 Python 3.8
2. Technical: 类型注解语法兼容、Union 替代 | 语法
3. Files: src/utils.py(完整修改后代码片段)、tests/test_parse.py
4. Errors: TypeError on Python 3.8 due to X | Y syntax → 改为 Union[X, Y]
5. Problem Solving: 先尝试 from __future__ 方案失败,最终用 typing.Union
6. User Messages:「帮我重构...兼容 Python 3.8」(逐字保留)
7. Pending: 无
8. Current: 重构已完成,测试通过
9. Next: 可能需要更新 type stubs
→ 原文不保留,摘要本身就是唯一记录。丢失的:中间调试细节、完整错误栈、Agent 的推理过程。核心差异:MemGPT 的摘要可以很短(反正原文在 Recall Storage 里),Claude Code 的摘要必须足够详细(因为这是唯一的记录,压缩后无法复原)。
Claude Code 压缩管线步进演示
初始 · 0/5
Auto-Compact 保留规则
- ✅ System prompt + CLAUDE.md(从磁盘重载,不受压缩影响)
- ✅ 所有用户消息(逐字保留在摘要中)
- ✅ 最近 3 个工具结果(硬保护)
- ✅ 当前任务 + 待办事项
- ❌ 早期工具输出原文(已被占位符替代)
- ❌ 中间推理过程(仅保留结论)
- ❌ 图片/文档原始内容
二、情节经验
模型推理的推理轨迹中往往能得到一些有利于下次推理的经验信息(skill),核心问题是:怎么让模型自动总结并利用这些 skill 让 Agent 下次做得更好?在 Memory 系统方面可以拆为三个维度:存什么(经验以什么形式保留)、怎么更新(新经验如何创建和迭代)、怎么召回(需要时如何加载到上下文)。早期的工作大多在探索要存什么,近期的研究开始聚焦于怎么有效更新、怎么与 RL 训练结合,提高模型的 skill 利用能力。
skill 的表示形式:早期探索
Reflexion(Shinn et al., 2023)用 Actor → Evaluator → Self-Reflection 构成 执行→评估→反思 闭环:仅在失败时写出自然语言反思,下轮注入 prompt 重试,用语言反馈替代调权重。
Evaluator 在不同场景下的实现方式
Evaluator 的核心职责是把模糊的「做得好不好」转化为二元信号,但在三种场景下实现方式完全不同:
- 推理任务(HotpotQA):精确匹配——答案对了就是成功,二元信号,无歧义
- 决策任务(AlfWorld):启发式规则——环境返回的 reward 信号判断是否达成目标状态
- 编程任务(HumanEval):LLM 自生成单元测试——Agent 先为任务写测试用例,再用测试结果作为评估信号。评估标准本身也由 LLM 生成,是最有意思的设计

Reflexion 系统架构:(a) Actor + Evaluator + Self-Reflection 三模块 + Memory 交互;(b) 类 RL 循环但更新发生在语言层。
展开说明 ▸
- Actor:LLM 策略模型,接收环境观察 + 短期记忆(当前轨迹)+ 长期记忆(历史反思),输出动作。
- Evaluator:将模糊的执行质量转化为二元成功/失败信号。三种场景三种实现:推理任务用精确匹配、决策任务用环境 reward、编程任务用 LLM 自生成的单元测试——评估标准本身也由 LLM 创建。
- Self-Reflection:失败时接收完整轨迹 + 评估信号,生成一段具体的、可操作的反思。比如「应该先找台灯再找杯子」。
- Memory:滑动窗口,仅保留最近 1-3 条反思。最简单的 episodic memory。
- 关键区别于 RL:不产生梯度,而是产出一段语言总结(semantic gradient),通过 in-context injection 影响行为。
三维度定位
存什么
自然语言反思(如「应该先定位台灯再拿杯子」),存入滑动窗口(1-3 条)。最朴素的经验形态。
怎么更新
单任务 retry 循环——失败 → LLM 生成反思 → 下轮重试。经验只在同一任务内累积。
怎么召回
最简单的硬加载——所有反思全量强制注入 prompt,无检索、无筛选。
Reflexion 证明了真实推理中获得的经验能被复用到下一次推理中,但单 query 反复推理获得的经验往往泛化性不足。
ExpeL 从多个 query 的成功/失败对比中提炼通用 insights。三个维度的变化:
- 存什么:① 完整的尝试轨迹;② 从轨迹中提炼的跨任务的抽象规则(如「先确认物品位置再行动」)。
- 怎么更新:创建和更新上依赖 GPT-4 做两类分析——(A) 对比同任务的成功/失败轨迹找关键差异;(B) 归纳多个成功轨迹的共性模式。
- 怎么召回:所有 insights 仍全量注入 + 向量检索 top-k 相关成功轨迹作为 few-shot。

ExpeL 系统架构:训练阶段收集经验 + 提炼 insights,推理阶段用 insights + 检索轨迹辅助一次性决策。
展开说明 ▸
- Experience Gathering:对训练集任务用 Reflexion 机制重试,成功/失败轨迹都存入经验池。
- Insight Extraction(核心创新):GPT-4 做两类分析——(A) 对比同任务的成功/失败轨迹,找出关键差异;(B) 归纳多个成功轨迹的共性模式。产出的 insights 经 ADD/UPVOTE/DOWNVOTE 投票机制筛选质量。
- Task Inference:所有 insights 全量注入 prompt + FAISS 检索 top-k 相关成功轨迹作为 few-shot。Agent 一次尝试即可。
- vs Reflexion:单任务重试 → 跨任务迁移;临时反思 → 持久化通用规则。
ExpeL 开始抽取更通用抽象的 insight,保留了未经处理的完整轨迹用于注入,这种粗细结合的方式被后续工作继承。主流的存储方式演变成了 SOP 抽象 + 可执行代码/流程细节。
课程式探索:LLM 自主设计任务
Voyager 把经验存成执行成功的代码,从文本反思迈向可执行 skill;由 LLM 基于环境反馈提出探索任务 驱动持续练级,验证通过的函数入库后可组合调用。召回侧改为按任务描述做向量检索 top-k,不再把整库反思全量塞进 prompt。
可执行代码更稳定,并且天然可被别的代码复用,由易到难,更容易探索出复杂任务的解决方案。


Voyager 架构与技能库:上图 — 课程学习 → 迭代写码 → 入库;下图 — 描述 embedding 入库,任务 query 检索 top-5 召回。
展开说明 ▸
- 存什么:可执行 JS 函数——验证通过的代码存入向量数据库,新技能可调用已有技能,能力以组合方式指数增长。
- 怎么更新:验证通过即入库(只增不改)——Iterative Prompting 不是整体重试,而是逐步调试:生成代码 → 执行 → 三路反馈(环境状态 diff 告诉「做了什么」/ JS 错误告诉「哪里炸了」/ LLM self-verification 判断「目标达到没」)→ 在上一版代码基础上修改,最多 4 轮。通过即存入 skill library,4 轮都没过就丢弃。
- 怎么召回:向量相似度 top-k——用任务描述 embedding 检索最相关的 5 个技能作为 few-shot,不再全量注入。
- Automatic Curriculum(图 1 左):GPT-4 根据 Agent 当前状态(背包、位置、已完成任务)提出难度递增的目标,即 LLM 基于环境反馈提出探索任务。
- Iterative Prompting(图 1 中):更像开发者调 bug 而非考试重试——GPT-4 生成 JS 代码 → 执行 → 三路反馈同时返回(环境状态 diff / JS 执行错误堆栈 / LLM self-verification 判断目标是否达成)→ 在上一版代码基础上针对性修改,最多 4 轮。
- Skill Library(图 1 右):验证通过的执行成功的代码以描述 embedding 为 key 入库;新任务时检索 top-5 相关技能注入 prompt。
- 入库流程(图 2 上):代码 → GPT-3.5 生成自然语言描述 → text-embedding-ada-002 编码 → 向量数据库。用描述做 key 是因为检索时 query 是自然语言。
- 检索流程(图 2 下):新任务 → GPT-3.5 生成解决建议 → 合并环境反馈作为 query → cosine similarity 检索 top-5 → 注入代码生成 prompt。
- 可组合性:
craftWoodenPlanks()内部调用mineWoodLog(),复杂技能站在简单技能肩膀上。
skill 的原则:粗细结合
AWM(Wang et al., 2024)从 Agent 成功轨迹里提取 SOP——带占位符的步骤流程(如「搜索 {product-name} → 加购 → 结账」),下次放进 prompt 作参考而非机械执行;按网站分组全量注入,可离线批量总结或在线边做边积累。
查看示例:AWM 归纳出的 workflow(来自原论文)
目标:在 Amazon 上搜索商品并按指定方式排序结果(Mind2Web 电商场景)
[textbox] Search Amazon → TYPE: {search-term}
[button] Go → CLICK
[span] Sort by: → CLICK
[option] {sort-option} → CLICK目标:计算两地之间的出行时间与距离(WebArena 地图场景)
fill('158', '{FROM_LOCATION}')
fill('163', '{TO_LOCATION}')
select_option('166', '{MODE_OF_TRANSPORTATION}')
click('171')
send_msg_to_user('The distance between {FROM_LOCATION} and {TO_LOCATION} is {DISTANCE} and the estimated travel time is {TIME}.')说明:花括号占位符(如
{search-term}、{FROM_LOCATION})将任务特定值抽象为通用变量,使同一 workflow 可复用于「搜索任意商品」或「查询任意两地距离」等不同具体任务。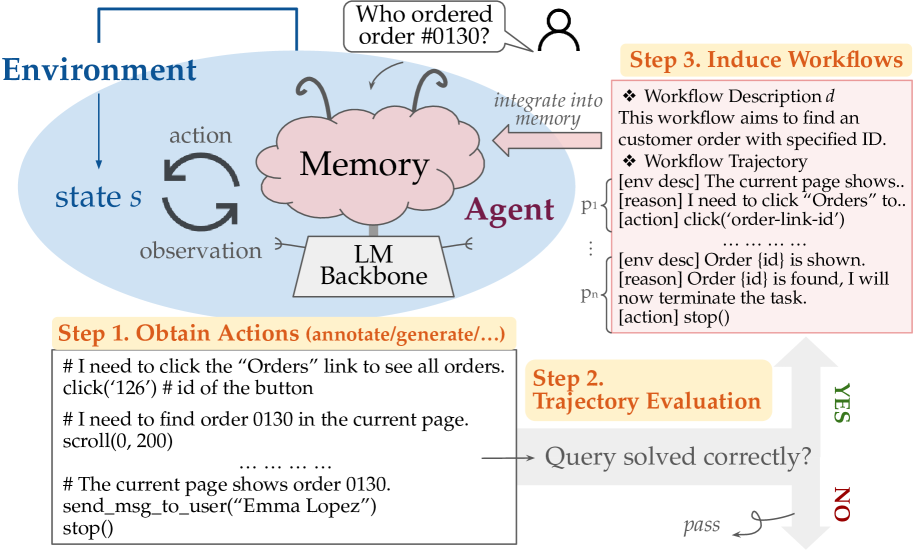
AWM pipeline 架构:agent 执行任务 → 归纳 workflow(NL 目标 + 参数化步骤)→ 整合到 memory → 指导后续任务。
展开说明 ▸
- Workflow Induction:从成功轨迹中提取子程序,将任务特定值替换为通用占位符(如 {product-name}),保证可复用性。
- Memory Integration:workflow 集合加入 agent 的 text-based memory,按网站分组。
- Memory Utilization:agent 执行新任务时参考 memory 中的 workflow 作为行动指导,自行决定是否遵循某个 workflow。
- 关键:workflow 作为 context guidance 而非直接执行的 action——动态环境下预定义动作序列太脆弱。
存什么
参数化 workflow(NL 目标 + 步骤序列 + 占位符),比 insights 更结构化但不是代码。
怎么更新
成功轨迹归纳(offline 批量 / online 滚雪球),只增不减,无遗忘机制。
怎么召回
按网站分组,访问哪个站就把该站所有 workflow 全量塞进 prompt(每站 ~7 个,token 可控)。Agent 自主判断用哪个。
局限:workflow 只增不减,无遗忘机制;全量注入依赖 workflow 数量少的假设;仅验证于网页导航场景。
ASI(Wang et al., 2025)延续 AWM 的在线归纳框架,把技能从文本 workflow 升级为可执行的 Python 程序:能实际跑通验证、能直接注册为 Agent 新动作,而不只是 prompt 里的参考说明。

ASI vs 文本技能对比:上方 AWM 将技能作为文本参考注入 memory;下方 ASI 将技能作为可执行程序直接扩展 action space,Agent 可以像调用 click() 一样调用 search_product()。
展开说明 ▸
- 相对 AWM:文本 workflow 只能放进 prompt,Agent 可能不跟、也无法执行验证;程序技能则扩展动作空间,调用一次函数即完成多步 click/fill/scroll。
- ① 归纳:从成功 episode 中由 LM 归纳 Python 函数(如
search_product(name)),封装多步原子操作为高层调用。 - ② 验证(核心):轨迹重写(用技能函数替换原始操作)→ 截断尾部(去掉
send_msg_to_user等直接给答案的步骤,否则重跑会「空过」验证、产生假阳性)→ 重跑检查:任务是否完成、是否真调用了新技能、调用是否引起环境变化。 - ③ 入库:三项全过才写入 skill library,后续可作为 Agent 可调用动作。
- 图中对比:上为文本参考式记忆增强;下为可执行程序式动作空间扩展。
原始轨迹(成功 episode)
click('[link] Marketing Reviews')
click('[link] Pending Reviews')
fill('[input] Search', 'pricing')
click('[button] Search')
send_msg_to_user('2')
↓ LM 归纳
def open_reviews():
click('[link] Marketing Reviews')
click('[link] Pending Reviews')
click('[link] Marketing Reviews')
click('[link] Pending Reviews')
def search_reviews(term):
fill('[input] Search', term)
click('[button] Search')
fill('[input] Search', term)
click('[button] Search')
↓ 重写 + 截断 + 重跑
✓ 任务完成
✓ 调用了新技能
✓ 环境发生变化
✅ 三项全过 → 技能入库,注册为 Agent 新动作
步骤 0 / 5
初始状态:Agent 完成了一个任务,留下一条成功轨迹(5 步原子操作)。
存什么
可执行 Python 函数——封装多步原子操作为高层 API(如
可执行 Python 函数——封装多步原子操作为高层 API(如
search_product(name)),直接注册为 Agent 新增动作
怎么更新
三重执行验证——轨迹重写 + 尾部截断 + 重跑检查(任务正确性 × 技能被调用 × 环境变化),全过才入库;按网站分库管理
三重执行验证——轨迹重写 + 尾部截断 + 重跑检查(任务正确性 × 技能被调用 × 环境变化),全过才入库;按网站分库管理
怎么召回
动作空间直接集成——技能函数注册在 action space 中,Agent 生成动作时直接可选,无需额外检索步骤
动作空间直接集成——技能函数注册在 action space 中,Agent 生成动作时直接可选,无需额外检索步骤
局限:验证依赖 LLM-based evaluator 判断正确性(非 ground-truth reward),且技能粒度和稳定性仍需进一步研究。
Skill 库自进化
至此,Skill 的顶层 SOP + 底层代码的范式基本已确定,研究重点转到怎样对现有的 skill 做更新。
RL 驱动的参数化进化
Skill 库的初始化创建和后续更新都依赖真实 rollout 轨迹;rollout 也是 RL 环节里成本最高的部分。有的工作开始探索这两个环节的融合,以更充分地利用 rollout 轨迹。
前述 Voyager/AWM 等把 rollout 经验外化成 skill,但 agent 多半只靠 prompt 注入来用,参数本身不会更会「用 skill」。SkillRL(Xia et al., 2026)用 teacher 把轨迹蒸馏进层次化 SkillBank(通用 skill 全量注入 + 任务 skill 向量 top-K,约 10–20× 压缩),再经 cold-start SFT 与 GRPO 训练;验证失败时 teacher 分析缺口并补 skill——核心是迭代 skill 库并进行 RL,提高模型的 skill 利用能力。

SkillRL 框架总览:base model 采集轨迹 → 经验蒸馏为层次化 SkillBank → cold-start SFT 教会 agent 使用 skill → GRPO 强化学习 + 验证失败驱动 skill 递归进化。
展开说明 ▸
- 经验蒸馏:成功轨迹 → 战略模式(关键决策 + 可泛化规律);失败轨迹 → 反面教训(失败点 + 应做什么 + 预防原则)。10–20× token 压缩。
- SkillBank 层次化组织:General Skills(环境通用策略)+ Task-Specific Skills(按任务类别分组的专属 heuristics),每个 skill 含 name / principle / when_to_apply。
- Cold-start SFT:teacher 生成 skill-augmented reasoning traces,微调 base model 使其学会检索、理解和应用 skill。
- 递归进化循环:GRPO 训练中,每个 validation epoch 对低成功率类别做失败轨迹分析 → teacher 发现 skill 盲区 → 生成新 skill 补入 SkillBank。
存什么
层次化 SkillBank——General Skills(跨任务通用策略)+ Task-Specific Skills(按类别的专属 heuristics)。每个 skill 含 name / principle / when_to_apply。
怎么更新
递归进化——RL 训练中 validation 失败触发 teacher 分析缺口,生成新 skill 补入库;技能库与策略共同进化,而非静态只读。
怎么召回
General Skills 全量注入 + Task-Specific Skills 向量 top-K 召回(基于 task description 与 skill 的 embedding 相似度)。
局限:技能进化依赖 teacher model 的分析质量;cold-start SFT + RL 训练成本较高(单次实验约 30 小时)。
美团的 Skill0(Lu et al., 2026)提出skill 内化:通过课程学习逐步缩小允许召回的 skill 数,让模型在 skill 不再放入上下文之后,仍能保持与载入 skill 时相近的性能。

Skill0 流程:离线按任务相关性分组 skill → 训练期 ICRL(skill + 视觉历史进 context)→ 动态课程按帮助性筛 skill、逐阶段缩减预算直至归零;推理期无 skill、无检索。

原文 Figure 5:训练动态对比——三组实验分别验证内化是否发生、优势是否来自参数而非偷看 skill、以及无 skill 推理时的性能上限。
展开说明 ▸
- (a) Skill0 自身:绿线 w/ skill、紫线 w/o skill。训练前期紫线明显更低;随课程推进紫线追上并在约 120 步后与绿线重合——说明能力已迁入参数,推理时不注入 skill 也接近带 skill 时的表现。
- (b) vs AgentOCR(均无 skill 推理):Skill0(绿)全程高于 AgentOCR(紫),差距随训练拉大,排除「只是训练时多看了 skill 才变强」。
- (c) vs GRPO / SkillRL(均无 skill 推理):GRPO(黄)早期涨得快但后期 plateau;SkillRL(紫)约 60–100 步见顶后撤 skill 性能明显下滑——能力未内化;Skill0(绿)起步慢但持续升至约 150 步,为三者最高。SkillRL 教会用 skill,Skill0 教会替代 skill。
子图 (c) 里有一条值得单独注意的曲线:SkillRL 在长期训练之后,对 skill 的依赖度在逐渐加深,导致训练后期在不载入 skill 的情况下反而出现性能下降。
存什么
训练期:按任务分组后的结构化 skill 文档(继承 SkillRL SkillBank)。推理期:库可完全不用,能力在参数里。
怎么更新
ICRL + 动态课程——Δk 筛选仍需要的 skill,阶段预算衰减至 0;已内化(Δk≤0)的技能从训练中移除。
怎么召回
推理无召回。训练期按任务相关性选 skill 组,阶段内按帮助性 top-M 注入(非 embedding 检索器)。
局限:依赖高质量初始 SkillBank 与帮助性评估(每个 skill 需有/无对照 rollout);实验主要在 ALFWorld、Search-QA,与 Trace2Skill 式「单份综合 SOP」路线互补而非替代。
延伸阅读:Skill0 方法图解
三、个性化记忆
核心问题:用户特定痕迹有不同的保留、检索和隐私规则,不应混入通用知识。跨会话对话记忆是这一层最典型的场景——需要从冗长历史中抽取、合并、检索与用户相关的 salient facts,而不是每次把全文塞进上下文。
Mem0(Chhikara et al., 2025)为跨会话对话维护持续更新的外部记忆库:每轮 (mt-1, mt) 触发一次 pipeline——先用 LLM 从当前交换中抽取候选事实(结合全局摘要与近期上下文),再检索库内相似条目并决定 ADD / UPDATE / DELETE / NOOP;答题时只做向量检索注入相关记忆(约 1.7k token,远低于 full-context 的 2.6 万+)。
处理管线 抽取
📋 摘要 S:Alice 与助手讨论饮食偏好
💬 近期:…上次提到喜欢中餐
用户 我改吃素了,以后不吃肉。
助手 好的,已记录你的饮食变化。
↓ LLM 抽取 φ(P)
候选事实 ω:「Alice 是素食主义者」
↓ 检索 top-10 相似 + Tool Call
向量记忆库 0 条
M1 · Alice 喜欢中餐
M2 · Alice 是素食主义者
❓ 推荐今晚吃什么?
检索到 M2 → 生成:「你是素食主义者,推荐素食餐厅或沙拉吧。」
步骤 0 / 6
初始:记忆库中有一条旧事实「喜欢中餐」。新一轮对话尚未进入 pipeline。

Mem0 架构总览:抽取阶段把消息 + 历史语境转为候选记忆;更新阶段与相似已有记忆比对后执行 ADD/UPDATE/DELETE/NOOP;中央向量库同时供检索与后续处理。
展开说明 ▸
- 输入流:每轮完整交互单元(用户消息 + 助手回复)触发 pipeline,适合流式对话场景。
- 双源语境(抽取):摘要
S提供全局主题;最近 10 条消息提供细粒度时序细节——二者互补,避免只靠摘要丢细节。 - 异步摘要模块:与主 pipeline 解耦,不阻塞记忆写入,保证抽取时
S尽量新。 - Tool Call 更新:不用单独分类器,由 LLM 根据候选事实与检索到的相似记忆之间的语义关系直接选操作。
- 向量库:dense embedding 支撑更新阶段的相似检索与查询阶段的记忆召回。
- 一句话总结:把「整段对话」压缩成「可维护的事实条目集合」,用显式增删改保持库内一致,而非静态 RAG 切块。
查看示例:记忆更新四操作(Appendix B 逻辑)
对候选事实 f 与已有记忆库 M 的判定逻辑:
- ADD:
f与库中无语义相似条目 → 生成新 ID 写入 - UPDATE:
f可补充已有记忆且信息更丰富 → 替换旧条目 - DELETE:
f与某条已有记忆矛盾 → 删除被否决的旧记忆 - NOOP:已存在或无需改动 → 跳过
实验默认 m=10(近期消息窗)、s=10(相似记忆数),抽取与更新均用 GPT-4o-mini。
存什么
从对话中抽取的 salient facts(自然语言记忆条目),每条带唯一 ID,存入向量数据库——不是原始 transcript 切块。
怎么更新
每轮消息对触发:LLM 抽取候选事实 → 检索 top-10 相似旧记忆 → tool call 执行 ADD/UPDATE/DELETE/NOOP;全局摘要异步刷新。
怎么召回
查询时 embedding 语义检索相关记忆注入 prompt;检索 p95 约 0.2s,总响应 p95 约 1.44s(LOCOMO)。
IFRAgent(Wu et al., 2025)改写用户 query,注入用户偏好细节:离线从演示轨迹 S(u,q) 并行提取显式 SOP p 与隐式习惯库 hi;在线对新 query RAG 相似历史 SOP,经 ℰ 生成流程、𝒲 将 hi 编入 q改、p改 后交 UI Agent——习惯经 rewriter 间接注入,而非直接塞进执行 prompt。
rewrite 示例
RAG + ℰ 只解决「这类任务大致怎么做」(得到通用 SOP 模板);Rewrite 才解决「这个用户要怎么做」——用一个小模型 𝒲 读入当前 query、当前 SOP、习惯库 hi,把 hi 里的偏好写进自然语言,输出给 UI Agent 的 q改 与 p改。不是向量检索,是文本改写。
输入 q(本轮用户话)
输入 p(ℰ 生成的 SOP)
输入 hi(离线积累的习惯描述)
→ 𝒲 改写 →
输出 q改、p改(带个人约束的指令)
改写前(通用模板,Step 5 结束)
q:「帮我点份晚餐」
p(SOP):
1. 打开美团
2. 搜索餐厅
3. 按评分筛选
4. 下单
𝒲
Rewrite
Rewrite
改写后(个性化,Step 6)
q改:「帮我点份晚餐,附近、川菜、中辣」
p改(SOP):
1. 打开美团
2. 搜索餐厅
3. 先按距离排序,再筛 川菜 + 辣度
4. 下单
hi 例:「偏好川菜、重辣;习惯先按距离再比评分」→ 被 𝒲 抄写/融合进 q改 与 p改 的步骤文案。UI Agent 只读改写后的文本,不直接读 hi。
步进演示:离线建库 → 在线个性化执行
离线 · 意图流提取
📱 演示:query「点外卖」+ 截图轨迹 S
↳ 并行
显式 Ae → SOP + embedding 入库
隐式 Ai → 习惯库 hi +=「偏好川菜、重辣」
在线 · 部署
新 query:「帮我点份晚餐」
RAG+(q′,SOP′) → ℰ 得通用 SOP p(未个性化)
【Rewrite】𝒲:q+p+hi → q改、p改
UI Agent 只执行 q改、p改
步骤 0 / 6
初始:用户尚未提供演示,显式 SOP 库与隐式习惯库为空。
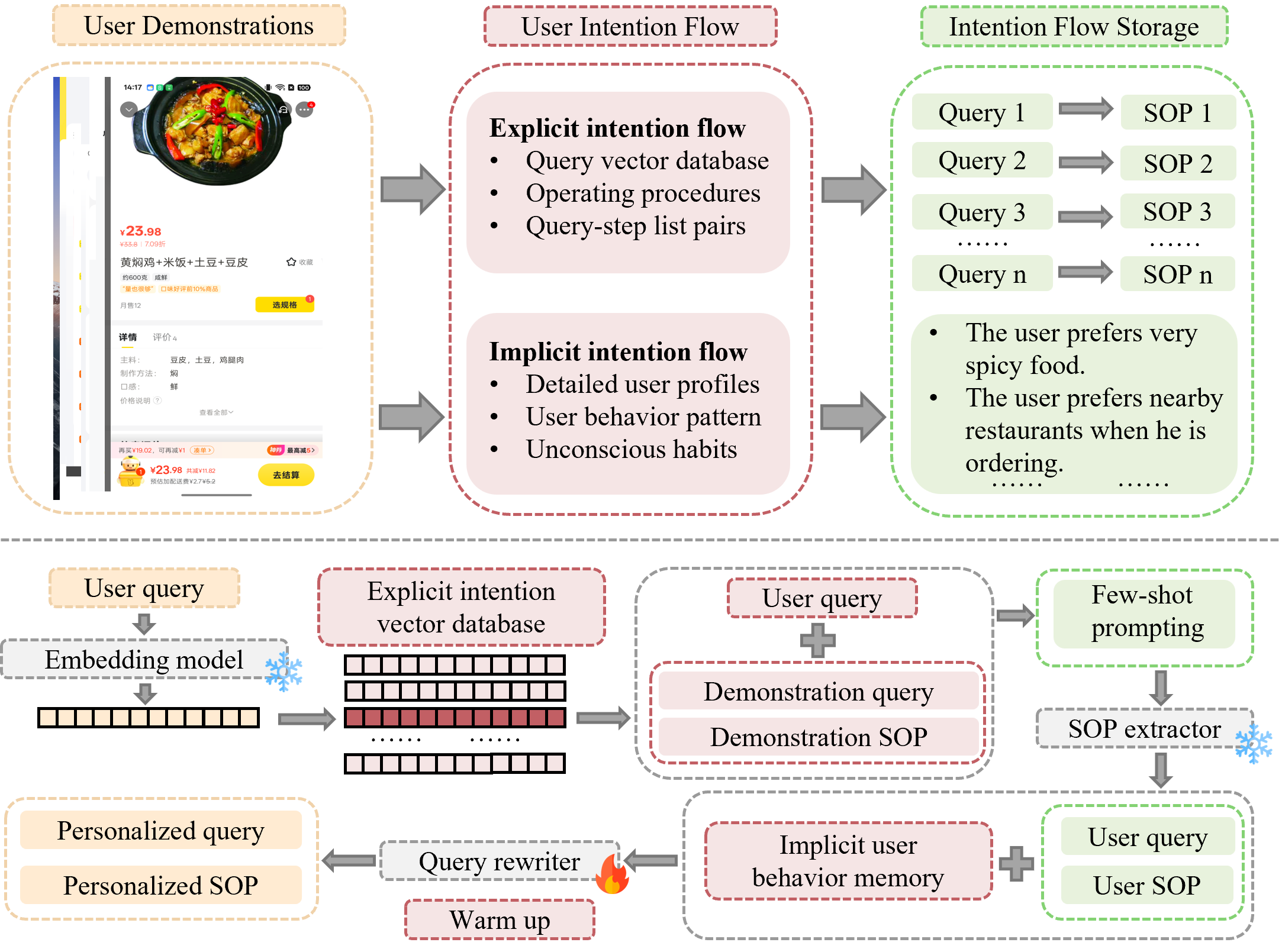
IFRAgent 全流程:上半部离线从演示提取显式 SOP 与隐式习惯;下半部在线 RAG + 改写后驱动手机 Agent。
展开说明 ▸
- User Demonstrations:多组 (query, 截图轨迹),用户无需标注偏好。
- Explicit flow:GPT-4o 从轨迹抽逐步 SOP,
ϕ(query)入向量库,供相似任务 few-shot。 - Implicit flow:同一演示增量写入用户习惯库
hi,跨 query 共享。 - SOP 检索线:embedding 相似度 > τ 时取历史 (q′, p′) → ℰ 生成新 SOP。
- 个性化改写线:𝒲(Qwen3-4B 蒸馏)输入 q, p, hi → 输出
q改,p改(论文写作 q̂、p̂)。 - 执行:UI-TARS 等 Agent 接收 q改, p改 + 当前屏幕,按用户习惯操作。
查看示例:点外卖任务的显式 SOP vs 隐式习惯
显式 SOP(per-query):「点外卖 → 1. 打开美团 2. 搜索餐厅 3. 按评分筛选 4. 下单」
隐式习惯(per-user):「偏好川菜、辣度中高;习惯先按距离排序再比评分」
Rewrite 前后(同任务):
- 改写前 p:按评分筛选 → 改写后 p改:先按距离,再筛川菜+辣度(来自 hi)
- 改写前 q:「帮我点份晚餐」 → 改写后 q改:补「附近、川菜、中辣」
Agent 只看到 q改/p改,不会直接读 hi 原文。
存什么
Per-user 两套存储:显式 (embedding, SOP) 对;隐式习惯库 hi(自然语言偏好描述,跨任务共享)。
怎么更新
离线:每段新演示跑 Ae 追加 SOP 对、Ai 增量更新 hi。在线不自动写库(需新演示)。𝒲 经 SFT 暖启动。
怎么召回
显式:query embedding 检索 top-1 SOP(阈值 τ)。隐式:全量 hi 送入 𝒲,不做向量检索。